Findit – Node.js 实现的磁力搜索引擎
2015-03-05 · 2,092 chars · 11 min read

更新
- AntColony 磁力链接爬虫 已开源:https://github.com/keenwon/antcolony
- Findit 已关闭
- 网上可能有一些磁力搜索站点,贴了这篇文章的链接,但都与我完全没有关系
废话写前头#
源起#
2013 底的时候,我从第一家公司离职,由于各种原因休息了一段时间,年后才入职新公司。休息的这段时间,除了搭建这个个人博客、看书、帮以前学校完成一个 CMS 系统(目前没有使用,使用 ASP.NET 实现的,后面可能会把代码放到 Github 上)外,还有一个大的发现,就是 Xiaoxia 写的一个磁力链接搜索引擎。相信大家都知道这是干什么的,粗略看完 Xiaoxia 写的介绍后,真是脑洞大开,兴趣满满,我第一次深切感受到技术的有趣。本打算自己开发一个出来玩玩,奈何对 ASP.NET/C# 只懂些皮毛,缺乏深入了解,写起来很累,又打算投入新的工作中,所以只得作罢。
2014 年加入新公司后,频繁的使用了 Node.js,渐渐的发现 Node 的强大,磁力搜索引擎的想法又重新浮现。可以说,这一年我大部分的学习都是围绕 “Findit 磁力搜索引擎” 展开的,看我博客近期写的文章就会发现:Redis、Mongodb、PM2、Elasticsearch、甚至 Centos 和 Nginx,都是 Findit 使用到的技术。在实践中学习,这本身也是花大力气做这件事的目的。
上线#
2014-10-25 网站正式上线。域名是 findit.so(so 域名一年后巨贵,切到了我的二级域名上 https://findit.keenwon.com),在 Digitalocean 上使用了三台 VPS:
- 第一台部署了 Findit 站点本身(express.js、nginx)和单个节点的 Elasticsearch
- 第二台部署了 Mongodb 数据库(目前有 300W 数据,每日新收录 1W+ 的数据)
- 第三台部署了 AntColony 磁力链接爬虫(后面细说)
好景不长#
但是好景不长,不用说大家也知道,使用 BT 种子下载的都是什么东西,盗版、色情充斥其中。本来还想放点 Google AdSense 让它自负盈亏的,结果还没一个月就收到了警告邮件,要求我整改,深知此问题无法有效解决,索性也就把广告给下了,每个月一两百的 VPS 钱还是出得起的(呵呵)。
另外一点就是,14 年 12 月,“带头大哥” 海盗湾被瑞典警方连窝端了,什么?你说这个关我 p 事?当然关我的事了。AntColony 从 DHT 网络中收集到资源的 infohash 后,要去种子托管网站下载种子文件,读取文件内容,收录到系统中才能被用户搜索到。海盗湾被查封的同时 Zoink 和 Torrage 这两个种子托管站也被封了(目前 Zoink 还活着),这就影响到了资源的收录。
海盗湾事件更重要的影响是,我被动摇了。很多国家禁止使用 BT 下载盗版资源,而国内大多数人用来干什么大家都懂的(我看的到用户搜索的关键字)。还有就是 BT 本身的特性,要大家一起下载才快,Findit 收录的资源,可能已经没什么人下载了,用户使用搜索到的磁力链接下载资源,很可能根本没有速度。这些都让我怀疑 “磁力链接搜索引擎” 存在的意义,只能以 “重在过程” 聊以自慰了:开发过程中,我确实学到不少。所以,可能不久的将来,findit 会被关闭,但我希望代码可以被留存下来,帮到需要它的人。好了废话到此为止。
相关知识#
这部分我不打算细说,google 都能搜出来,我只列一下我觉得比较好的资料:
- 最关键的就是 BitTorrent.org 上的文档
- 最初提到的 Xiaoxia 的那篇文章,粗略的提到了实现原理。
- P2P 中 DHT 网络介绍
- Kademlia 协议
- Kademlia 详解
- Kevin Lynx 写的几篇文章
- Torrent 文件结构解析
大概就这些了。
AntColony#
AntColony(Github)是 findit 磁力搜索引擎的核心。用来在 DHT 网络中,收集活跃资源的 infohash,下载并解析资源的种子文件,存入数据库等。AntColony 是若干功能的合集,也可以单独运行其中的部分功能,所以起 “蚁群” 这个名字也是很贴切的。主要分一下几块:
- worker:爬虫,收集资源 infohash,可以同时启动多个进程的 worker,提高效率
- male:根据收集来的 infohash 去下载种子文件
- female:将种子文件录入数据库
- queen:简单的入口,启动 pm2 运行 worker,male 和 female
先来张 AntColony 和谐运行的靓照:
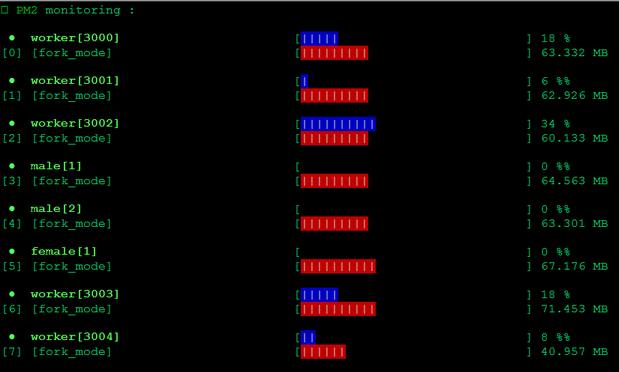
目前启动 5 个 worker 使用 3000-3004 的端口,2 个 male 和 1 个 female。
使用 Mongodb 储存数据,这没什么好说的;使用 pm2 维护和监控 node 进程,也没太多要说的,重点说下 Redis。Redis 里暂存的数据大概是这样的:
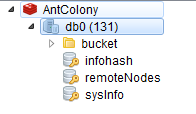
比较大的一个 K 桶(bucket);infohash 就是已经收集到的 infohashs(worker 收集来的,male 会用来下载种子);remoteNodes 是 worker 新认识的节点,会依�次“拜访”的,目前只保存最新的 10w 个(一方面我的 VPS 内存小,另一方面真没必要记录太多);sysInfo 会记录一些统计信息,例如发出多少次请求,累积收集多少 infohashs,目前已经发出 15 亿次 Request,这个频率是可控的,worker 太疯狂的话,VPS 扛不住。
下面简单说下运行方法,安装好 node,pm2,redis,mongodb 之后,执行 npm install 下载依赖的包,在根目录运行 node startup worker 3000 启动一个 worker 监听 3000 端口;运行 node startup male 1 启动 id 为 1 的 male(female 同理)。
mongodb-to-elasticsearch#
刚才说 AntColony 的时候没提到 Elasticsearch。Elasticsearch 是一个非常赞的实时分布式搜索引擎,惊人的强大和便捷,可以方便的在 Node 环境中使用 elasticsearch.js 操作。但是在实际使用中发现个问题,female 将种子文件解析好后,存储在 mongodb,再存储在 Elasticsearch,这个过程效率很低。经常会堆积大量种子文件处理不过来。另一方面,没有必要那么 “实时”,既浪费资源有增加了 Elasticsearch 的压力。所以就搞了 mongodb-to-elasticsearch 这个小工具,每天执行一次 mongodb 到 Elasticsearch 的数据同步。代码很简单,有兴趣的可直接看 Github 上的代码。
Findit#
Findit 是基于 Express.js 开发的一个小网站,只有一个简单的功能,就是查 Elasticsearch。有了 AntColony 和 mogodb-to-elasticsearch 就有了数据,想怎么玩都随你了,不多说。
存在的问题#
虽然稳定运行中,但是任然存在几个问题:
1、需要足否大的内存运行 AntColony。目前 AntColony 的 VPS 内存是 1G,Redis 占用了一部分,剩下可用的内存是 500M 左右,如果大于遇到 700K 的种子文件(大概的),female 就会卡住解析不存在,内存占用率不断提高,直到被 PM2 重启。

由于 female 是随机取出种子文件解析的,所以一段时间后还会遇到问题文件,继续卡住,如此不断的重复……,目前的解决办法,就是移走大文件,在自己电脑上运行 female 解析。当然不差钱的人可以用性能更强悍的机器。
(这其实可以解决的,当时对 node.js 了解还不够深入,现在懒得改了)
2、目前 mongodb-to-elasticsearch 是手动执行的。先停止 female,然后程序会把上次执行时间节点后,新增的数据同步过来。效率还不错,1W 多的数据几十秒就好了。但是手动执行还是太麻烦,下一步优化的方向是定时执行或者优化 female,直接同步 Elasticsearch。
最后#
前面也提到了,可能不久后会把 findit 关闭,如果大家有好的想法可以留言讨论。

