ES5 和 ES6 中的继承
2016-01-16 · 305 chars · 2 min read

Javascript 中的继承一直是个比较麻烦的问题,prototype、constructor、__proto__在构造函数,实例和原型之间有的复杂的关系,不仔细捋下很难记得牢固。ES6 中又新增了 class 和 extends,和 ES5 搅在一起,加上平时很少自己写继承,简直乱成一锅粥。不过还好,画个图一下就清晰了,下面不说话了,直接上图,上代码。
2016-01-16 · 305 chars · 2 min read
Javascript 中的继承一直是个比较麻烦的问题,prototype、constructor、__proto__在构造函数,实例和原型之间有的复杂的关系,不仔细捋下很难记得牢固。ES6 中又新增了 class 和 extends,和 ES5 搅在一起,加上平时很少自己写继承,简直乱成一锅粥。不过还好,画个图一下就清晰了,下面不说话了,直接上图,上代码。
2015-12-21 · 282 chars · 2 min read
这次说的不是什么大问题,但是出现问题后很难排查。最近一个项目用了大量的 CSS3 动画,使用 PostCSS 的 autoprefixer 自动加前缀,兼容 IE10 以上的所有浏览器,但是在 chrome 开发�完毕,做兼容测试的时候,却发现 IE10、IE11 的 opacity 失效了。百思不得其解……
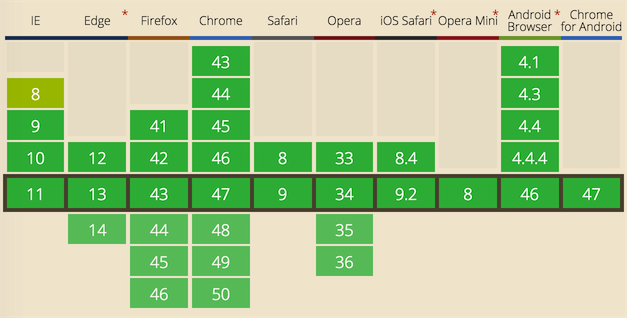
万幸的是并不是所有的 opacity 都失效了,对比生效和失效的代码,终于发现,IE10、11 和 chrome 等浏览器,在处理 opacity 的继承性问题上,存在差异。简单来说就是,父元素没有定位,子元素使用了定位属性 position(脱离文档流),IE 下子元素不继承父元素的 opacity,而其他浏览器会继承。
2015-11-07 · 610 chars · 4 min read
webpack 是一个在客户端构建和加载模块的工具,本文介绍如何基于 webpack 写 ES6 代码。文中相关代码请查看 github 项目:webpack-es6-demo。
webpack 最显而易见的优点是:
2015-11-03 · 1,482 chars · 8 min read
这次介绍下自己搭建的前端开发环境:fede2(https://github.com/keenwon/generator-fede2)。今年 6 月底入职新公司,经过一段时间的熟悉后,开始渐渐参与到前端开发,发现不少问题:
做了几个简单需求,前端调用不到后端的接口,各种跑不起来,各种环境(至少有测试和开发)参数要手动配置,前后端联调的时间超长,测试过程中 bug 极多,程序质量极低……终于忍无可忍,开始动手搭建合适的前端开发环境,于是就有了 fede 和 fede2。
2015-11-02 · 550 chars · 3 min read
入职的新公司一直都有做产能统计,简单来说就是在 url 后添加 source,记录是哪个页面哪个产品引入的流量。在做某项目的新版本首页时,运营提出一个 SEO 需求,希望首页的 source 参数能再用户点击的时候动态添加,而不会被搜索引擎爬到带 source 的链接。我虽然对 SEO 表示不屑,但这需求简单的很,就应了下来,可是由此引出一个诡异的 bug。
动态添加参数的方案很简单,代码如下:
在 a 标签添加 data 自定义参数
<a href="http://github.com" data-argu="source=index">首页</a>
2015-07-03 · 74 chars · 1 min read
2015-03-05 · 2,092 chars · 11 min read
更新
2013 底的时候,我从第一家公司离职,由于各种原因休息了一段时间,年后才入职新公司。休息的这段时间,除了搭建这个个人博客、看书、帮以前学校完成一个 CMS 系统(目前没有使用,使用 ASP.NET 实现的,后面可能会把代码放到 Github 上)外,还有一个大的发现,就是 Xiaoxia 写的一个磁力链接搜索引擎。相信大家都知道这是干什么的,粗略看完 Xiaoxia 写的介绍后,真是脑洞大开,兴趣满满,我第一次深切感受到技术的有趣。本打算自己开发一个出来玩玩,奈何对 ASP.NET/C# 只懂些皮毛,缺乏深入了解,写起来很累,又打算投入新的工作中,所以只得作罢。
2014 年加入新公司后,频繁的使用了 Node.js,渐渐的发现 Node 的强大,磁力搜索引擎的想法又重新浮现。可以说,这一年我大部分的学习都是围绕 “Findit 磁力搜索引擎” 展开的,看我博客近期写的文章就会发现:Redis、Mongodb、PM2、Elasticsearch、甚至 Centos 和 Nginx,都是 Findit 使用到的技术。在实践中学习,这本身也是花大力气做这件事的目的。
2014-12-12 · 1,648 chars · 9 min read
Elasticsearch 中,内置了很多分词器(analyzers),例如standard (标准分词器)、english (英文分词)和chinese (中文分词)。其中standard 就是无脑的一个一个词(汉字)切分,所以适用范围广,但是精准度低;english 对英文更加智能,可以识别单数负数,大小写,过滤 stopwords(例如“the”这个词)等;chinese 效果很差,后面会演示。这次主要玩这几个内容:安装中文分词 ik,对比不同分词器的效果,得出一个较佳的配置。关于 Elasticsearch,之前还写过两篇文章:Elasticsearch 的安装,运行和基本配置 和 备份和恢复,需要的可以看下。
Elasticsearch 的中文分词很烂,所以我们需要安装 ik。首先从 github 上下载项目,解压:
cd /tmp wget https://github.com/medcl/elasticsearch-analysis-ik/archive/master.zip unzip master.zip cd elasticsearch-analysis-ik/
2014-12-10 · 960 chars · 5 min read
距离上次讲Elasticsearch 的安装已经快一个半月了,作为一个半路出家的前端开发,简单的使用中也体验到了 Elasticsearch 的强大。目前在一个自己开发的小站点中,使用 Elasticsearch 索引了近 200W 简单数据,占用资源极小,搜索速度极快。下一步打算优化一下分词(目前使用的是标准分词器),所以想先备份一下,于是有了今天的文章。
Elasticsearch 的一大特点就是使用简单,api 也比较强大,备份也不例外。简单来说,备份分两步:1、创建一个仓库。2、备份指定索引。下面一步一步来:
2014-12-03 · 801 chars · 5 min read
刚到公司的时候,做了几个通用 js 组件,原生 js 写的,所以积累下一些比较好的代码片段,经过几次反复使用,质量还是比较有保证的。太长时间没写博客,这里分享出来刷刷人气。文章中的代码都在gist上同步了。
Handlebars等模板引擎非常好用,但是比较重量级,对于组件来说显然是不合适的,这里分享个简单的模板引擎,原生 js 实现:
