基于 Web Vitals 的前端性能优化实践
2023-10-17 · 12,846 chars · 65 min read

1. 性能指标#
在做性能优化之前,首先要明确相关指标。我们要带着明确的目标和方向去做优化,而不是随意的压压图片、加个预加载了事。
明确相关性能指标,也就是要明确:
- 衡量哪些性能指标?
- 为什么是这些指标?
- 这些指标该如何测量?
- 性能上,怎样算好,怎样算不好?
1.1 传统性能指标#
以前,前端有很多常用的性能指标,例如:
- FP(First Paint)
- TTFB(Time to First Byte)
- FCP(First Contentful Paint)
- SI(Speed Index)
- FMP(First Meaningful Paint)
- TTI(Time to Interactive)
- FCI(First CPU Idle)
Lighthouse V5 版本,主要测量的就是 FCP、SI、FMP、FCI、TTI 等几个指标。
这些「传统」的性能指标,和基于 Lighthouse 的性能测量,其实存在一些明显的问题。
比如,一些指标,虽然依然具有参考价值,但并不能很好的体现用户侧的真实体验。像 TTI,它的计算过程很复杂,要求有 5s 的静默窗口(无长任务 & 小于两个 GET 请求),然后沿着时间轴反向搜索 FCP 后的最后一个长任务,即为 TTI 时间。TTI 体现的是页面要多久才能具备完整的可交互性,但并不代表在此之前用户的交互都无法得到响应。当前一些比较复杂的前端应用,可能会分块按需加载,或者异步的延迟加载,都有可能把 TTI 时间拉得更长。所以,TTI 和 FCI 这类指标就显得有些过于「理论」了,脱离了实际的应用场景。
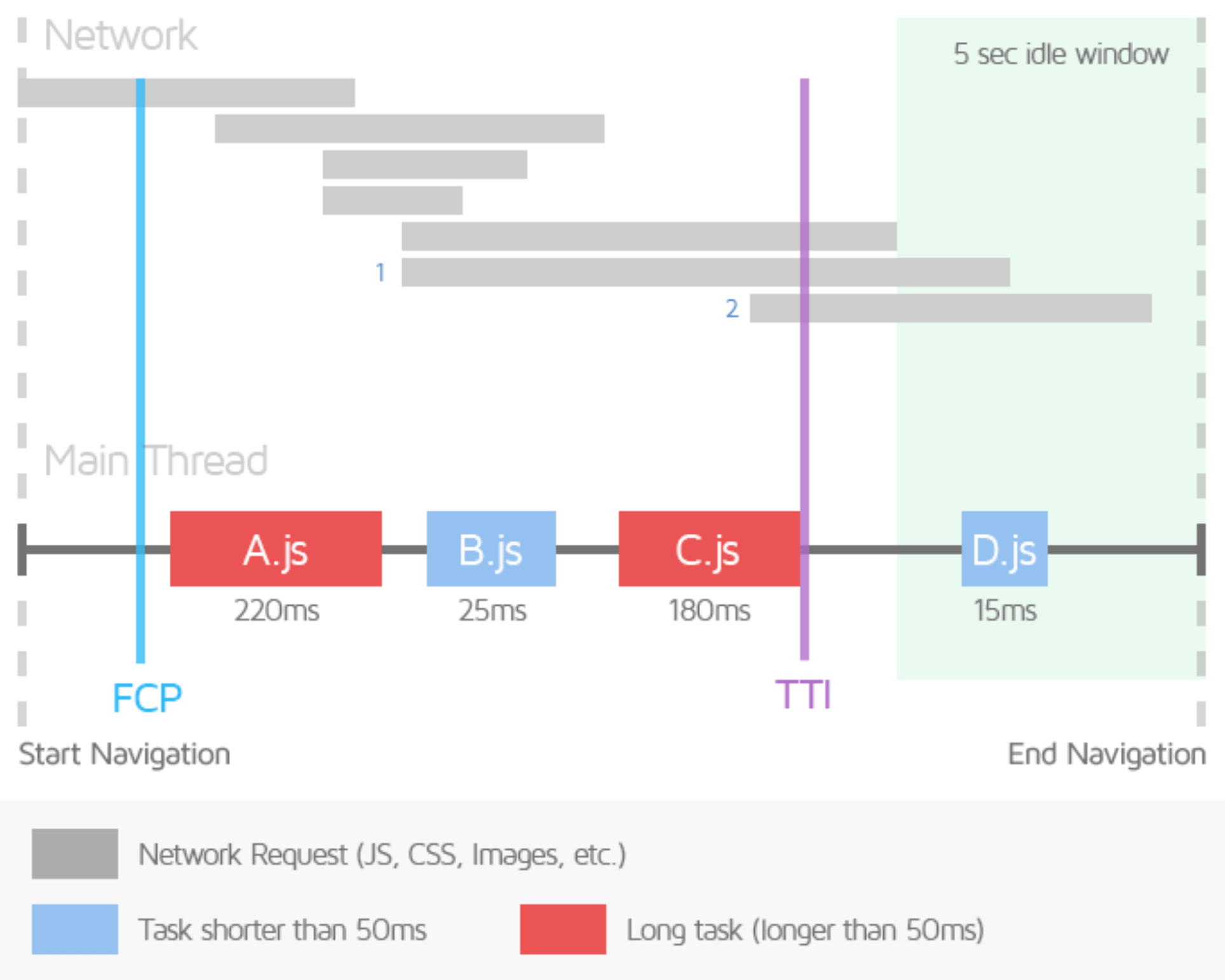
另外还有一点就是,以往测量前端性能,大多是使用 Chrome DevTools 自带的 Lighthouse,最多开一个「无痕窗口」来屏蔽浏览器扩展的影响。这样的测量方式,同样不能很好的反映用户的实际体验。在用户的真实使用场景里,网络环境、设备情况、甚至是用户个人账号情况,都可能极大的影响性能和体验。
1.2 Web Vitals#
所以基于此,2020 年 5 月,作为改善网络用户体验的持续举措的一部分,Google 推出了一套以用户为中心的标准化指标 —— Web Vitals。我们团队从 21 年底开始,一直都是基于 Web Vitals 来衡量和优化性能的。
1.2.1 概述#
Web Vitals 包含三个「核心指标」,也就是 Core Web Vitals(CWV):

其中,LCP 表示页面的「最大内容绘制」,用来衡量页面的加载性能。相比于其他指标,从用户的视角看,最大内容的绘制时间更能代表页面加载的速度。
FID 表示页面的「首次输入延迟」,用来衡量页面的交互性。例如当用户点击某个按钮时,程序要等多长时间才能响应。
CLS 表示页面的「累积布局偏移」,用来衡量页面的视觉稳定性,避免页面的闪烁给用户带来较差的体验。
Lighthouse 从 V6 版本开始,删除了一些旧指标,添加了 LCP、FID、CLS。目前最新版本的 Lighthouse V10,只包含 FCP、TBT、LCP、FID、CLS 五个指标。
上面图片里已经标识了 Google 官方对各个指标 good、need imporvement、poor 的定义。不过大家也可以根据团队的实际情况来定义基准线。
Note
说明:这里没有从概念上严格的区分 Web Vitals 和 Core Web Vitals。Core Web Vitals 仅包含 LCP 等三个指标,是 Web Vitals 的核心子集。而 Web Vitals 是个更广泛的概念,包含 TTFB、FCP、TBT 等更多的指标,这些指标很难在用户端实际测量,不是以用户为中心的指标,所以我们一般只作为辅助工具和补充。本文主要关注 Core Web Vitals。
1.2.2 优势、不足与发展#
新的 Core Web Vitals 一定程度上解决了传统指标的问题。
首先是更加系统化。相比于之前众多碎片化、理论化的指标,Web Vitals 提炼了三个核心指标。像加载性能,就全部收敛到了 LCP 上,避免了过往优化单一指标,数据效果明显,但体检提升不大的尴尬。
其次是完全「以用户为中心」��。比如新增的 CLS,这个概念在 Web Vitals 之前提到的比较少,但是相信大家都遇到过。设想,网络不好的时候,打开一个页面,我要点的按钮已经展示出来了,但当我点下去的时候,按钮上方的广告加载完成,将按钮挤了下去,直接点在了广告上......所以,视觉稳定性作为影响用户体验的关键,也纳入到了核心指标内。除了指标方面的转变,测量方式上同样也更倾向于使用基于真实用户的数据采集(这个在下一节聊)。
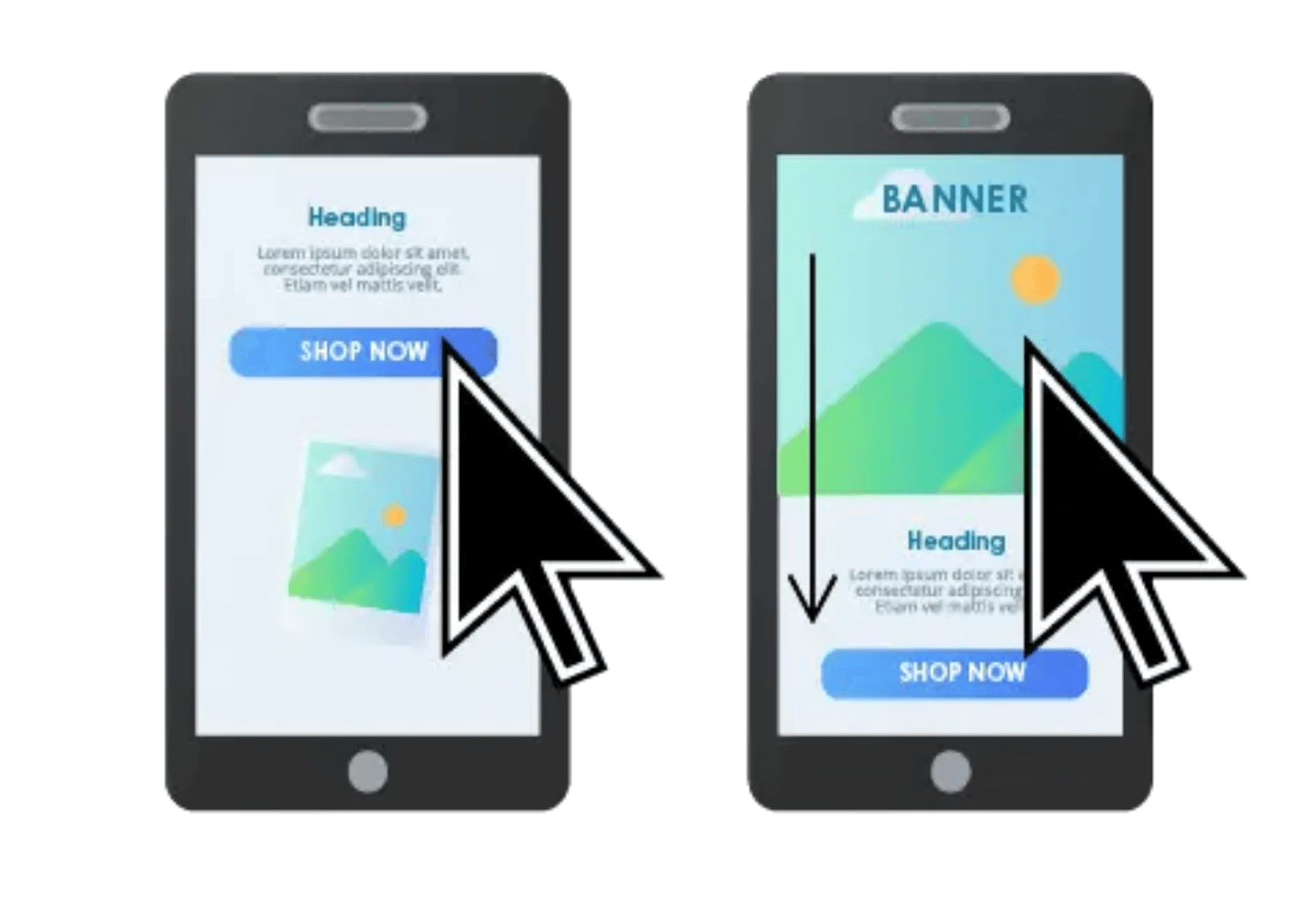
Web Vitals 并不完美,依然也存在一些不足。比如说 FID,它仅考虑第一次交互动作时的延迟,一些复杂的 Web APP,比较耗费性能的部分,往往不在页面刚启动的时候,而是贯穿整个用户使用周期的。近期 Chrome 团队提出了新的指标 —— INP (Interaction to Next Paint),相比于 FID 只测量首次交互的延迟,INP 关注用户与页面进行的所有交互的延迟。预计 24 年 3 月,INP 会取代 FID。
Web Vitals 就是目前最佳的性能度量指标,大家是很有必要仔细了解他们的定义、计算方式等,这里就不再进一步展开了。下面,咱们聊一下「性能检测工具」。
2. 检测工具#
这部分就简单介绍下。要想真正要熟悉它们,还是得实际用起来,在实践中积累。
「检测工具」根据数据源的不同,大致上了可以两类:
- 基于真实用户的数据
- web-vitals
- Chrome 用户体�验报告(CrUX)
- 基于实验室数据
- PageSpeed Insights
- Chrome DevTools
- Lighthouse
- Web Vitals Extension
这里面的 CrUX,是来自「数百万」个网站上的真实用户体验数据的「公共数据集」;PageSpeed Insights 是个在线的工具,结合了 Lighthouse 的实验室数据和来自 CrUX 的真实用户数据。这两个实际用的比较少。
总的来说,建议以 web-vitals 采集的真实数据为准,衡量页面性能。开发和优化过程中,使用 Chrome DevTools、Lighthouse、Web Vitals Extension 等查看页面的加载和运行情况,分析判断优化的方向和方法。
下面简单说下几个比较常用的。
2.1 web-vitals#
刚才也提到过了,页面实际的性能表现,还是应该以用户侧的真实采集的数据为准。
Google 的 Chrome 团队开源的同名库: web-vitals ,就是用来采集用户侧的性能数据的。
import {onCLS, onFID, onLCP} from 'web-vitals';
function sendToAnalytics(metric) {
// Replace with whatever serialization method you prefer.
// Note: JSON.stringify will likely include more data than you need.
const body = JSON.stringify(metric);
// Use `navigator.sendBeacon()` if available, falling back to `fetch()`.
(navigator.sendBeacon && navigator.sendBeacon('/analytics', body)) ||
fetch('/analytics', {body, method: 'POST', keepalive: true});
}
onCLS(sendToAnalytics);
onFID(sendToAnalytics);
onLCP(sendToAnalytics);
前端部分使用起来还是比较简单的,但是要配合一些服务端的数据存储、�查询和可视化工具才行。
这是我公司的 wapm 工具:
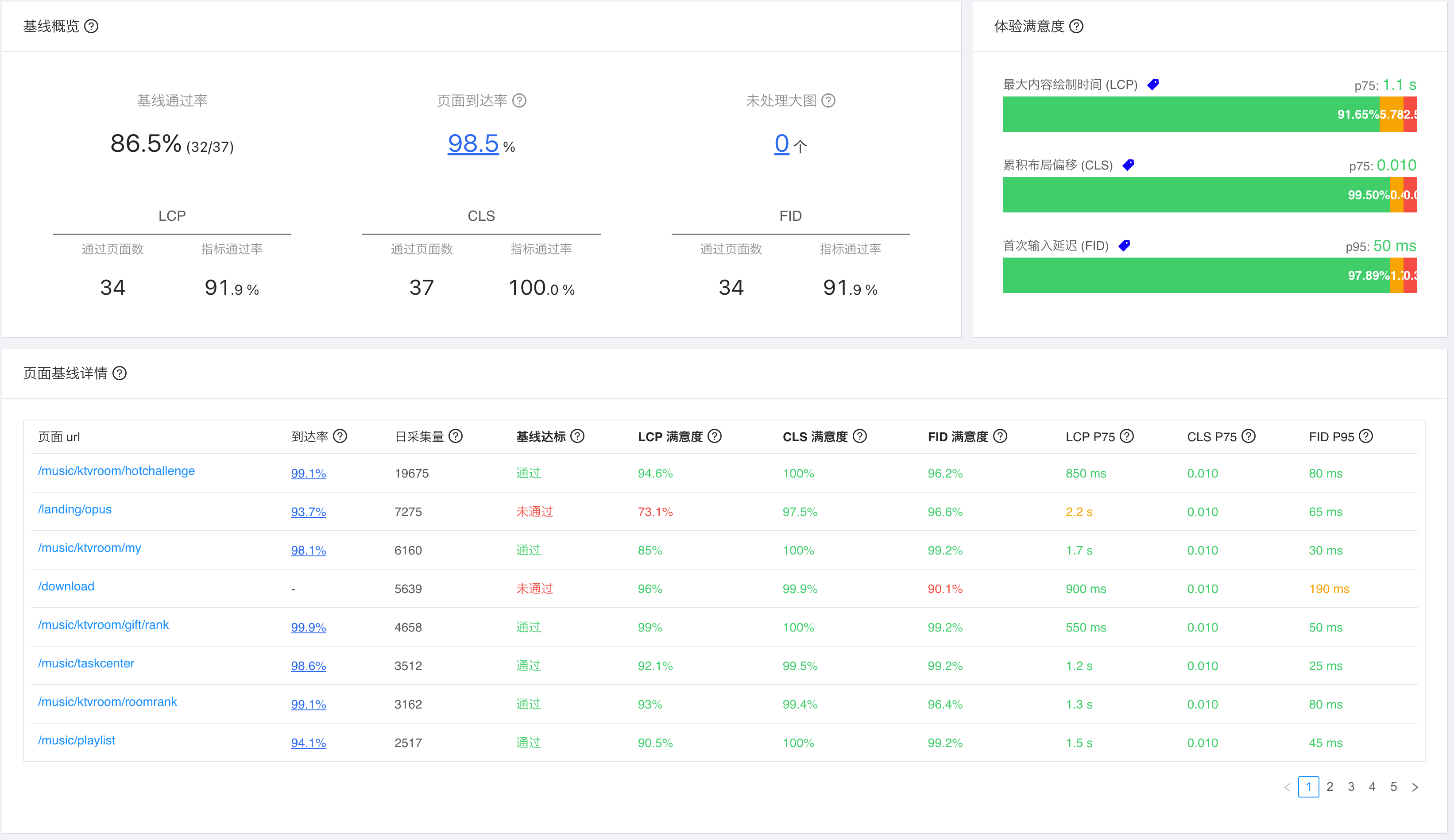
wapm 这类的前端基建,需要一定开发成本。如果团队没有类似的基建,也可以考虑使用一些开源的数据可视化工具,比如 Grafana
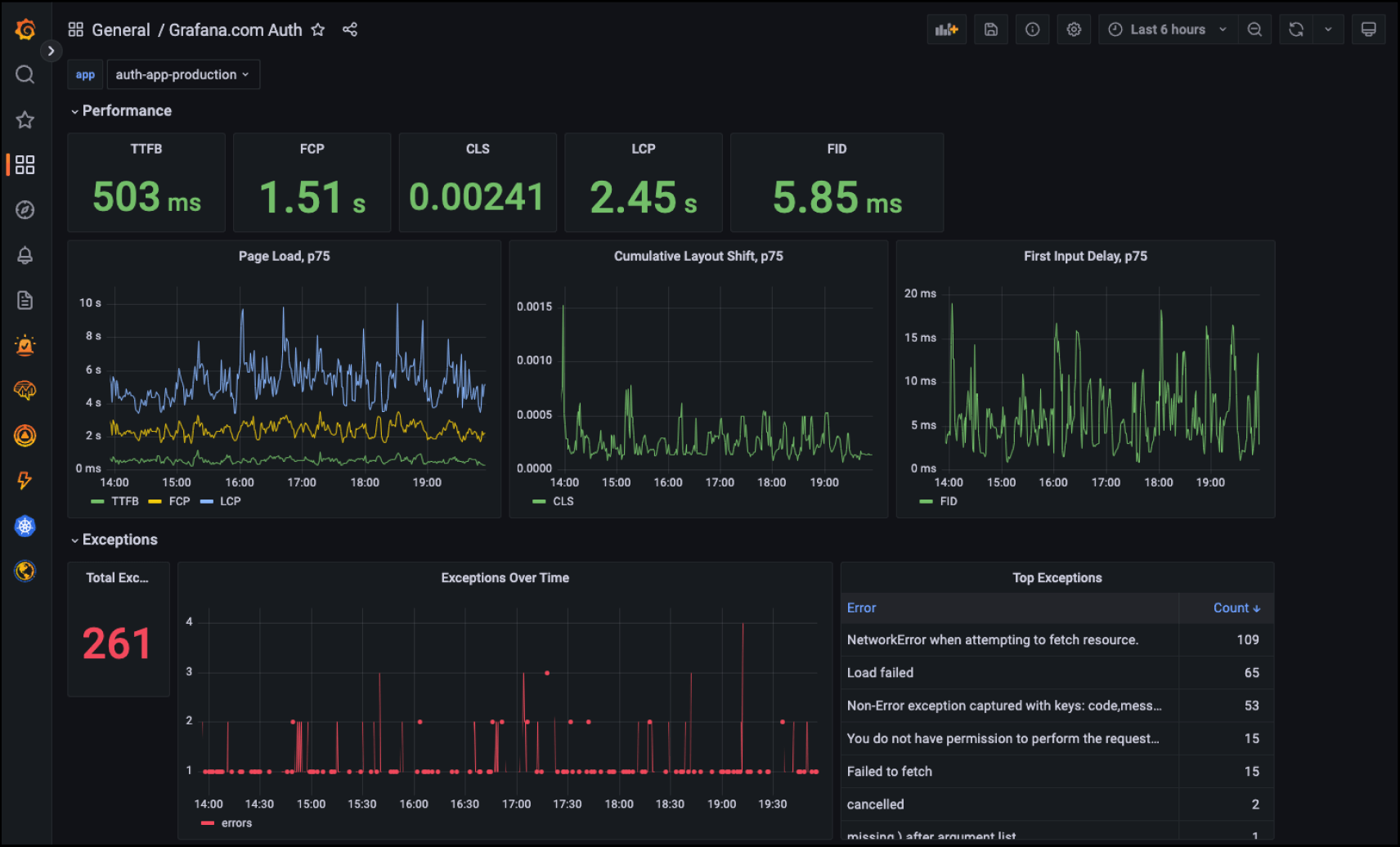
2.2 Chrome DevTools 和 Lighthouse#
Chrome 的 DevTools 应该每个前端开发用得最多的工具之一,它的 Performance 面板和 Lighthouse 面板都可以测量性能。
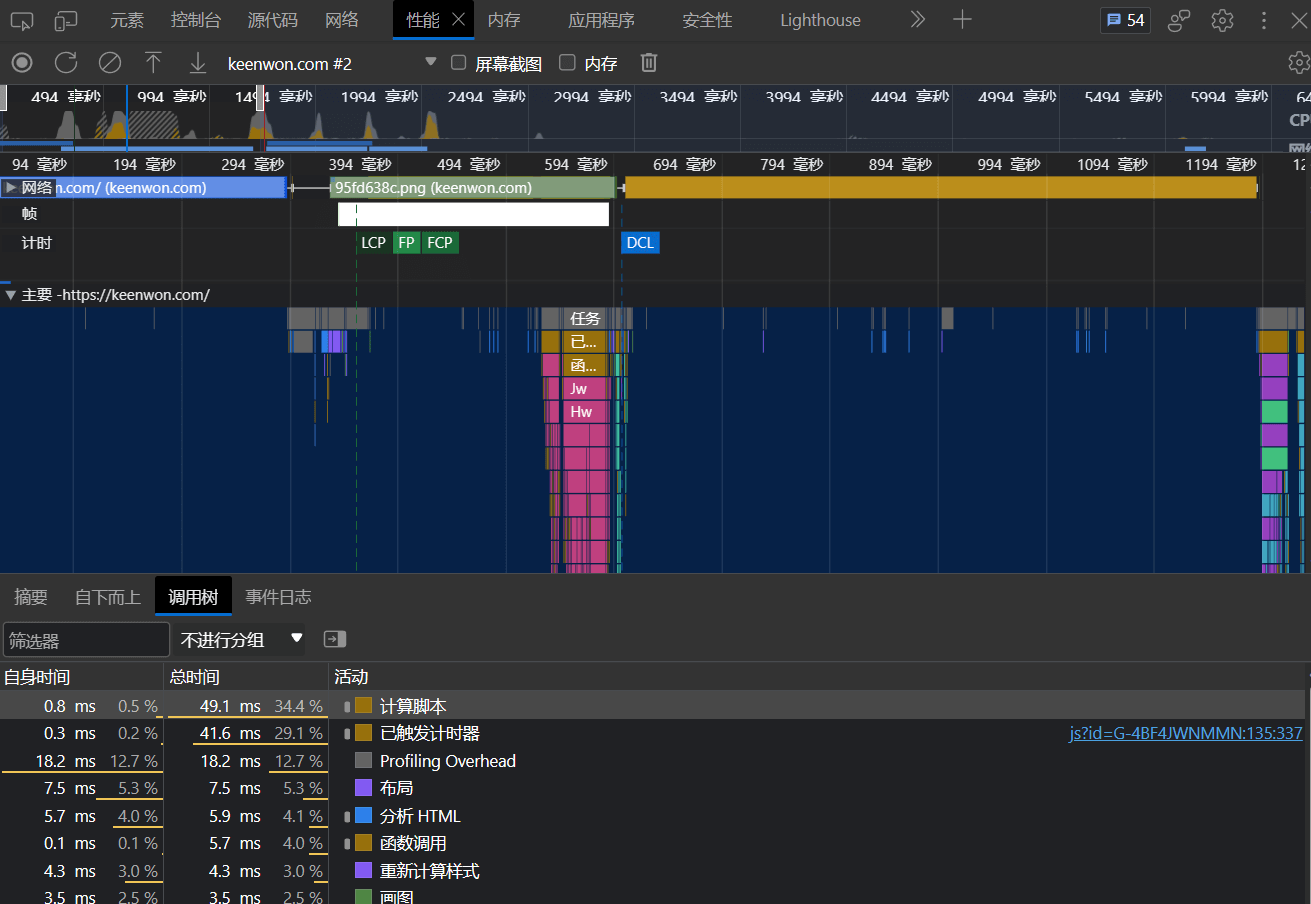
DevTools 是前端弄清楚「页面加载&运行情况」的重要手段,唯一要注意的就是屏蔽掉「浏览器扩展」的影响,打开隐身窗口或者新建一个空白账号都可以。
2.3 Web Vitals Extension#
接下来介绍几个浏览器扩展,用起来也很方便,大家可以安装上试试。
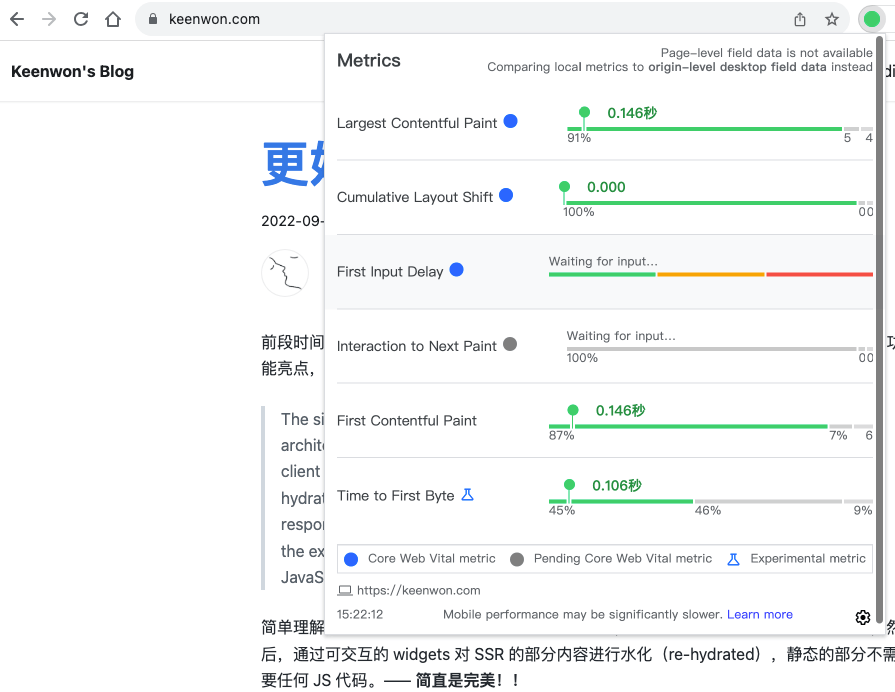
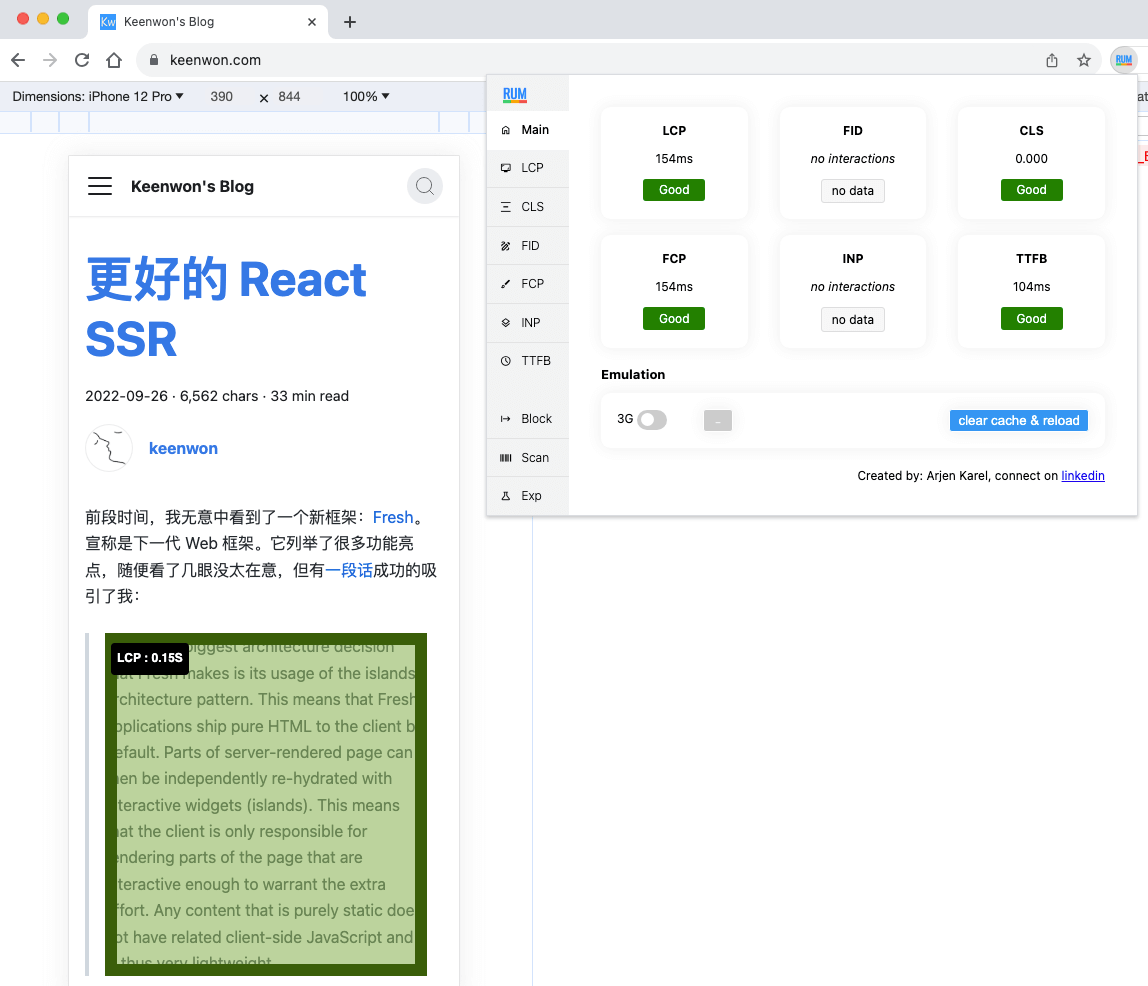
Chrome 扩展:Core Web Vitals Visualizer:UI 美观,功能完备,可以方便的查看页面的 LCP、CLS 等。
3. 系统级优化实践#
在了解「性能指标」和「检测工具」之后,就是真正的重头戏——「性能优化」 了。
根据实践过程中的总结,所有的优化手段,大致可以分为两类:
- 系统级优化:顾名思义,就是系统级的优化手段,通常不针对具体某个功能或指标。比如,前端的架构选型,项目的脚手架、模板、编译构建,组件库等等,还有服务端、客户端配合做的一些优化。
- 针对性优化:大多是针对某个具体的指标,某种具体类型的资源。手段较多,甚至矛盾(域名分散 vs 域名收敛),需要具体情况具体分析。比如优化资源的加载优先级、动态 import、切分长任务等等。
不过这个分类法不算特别严谨,这里主要为了结构更加清晰。接下就挑一些效果比较明显的措施,逐个聊聊,首先是系统级优化。
3.1 高性能架构#
先来看架构方面的。目前前端比较常见的渲染模型,主要就是 CSR 和 SSR。也就是「客户端渲染」和「服务端渲染」。
3.1.1 SSR#
SSR 的核心就是在服务端把页面渲染出来,具体的架构可以随意发挥,细节这里就不展开讲了,我们主要关注于性能问题。这是我几年前一个项目的流程图,可以简单参考下:
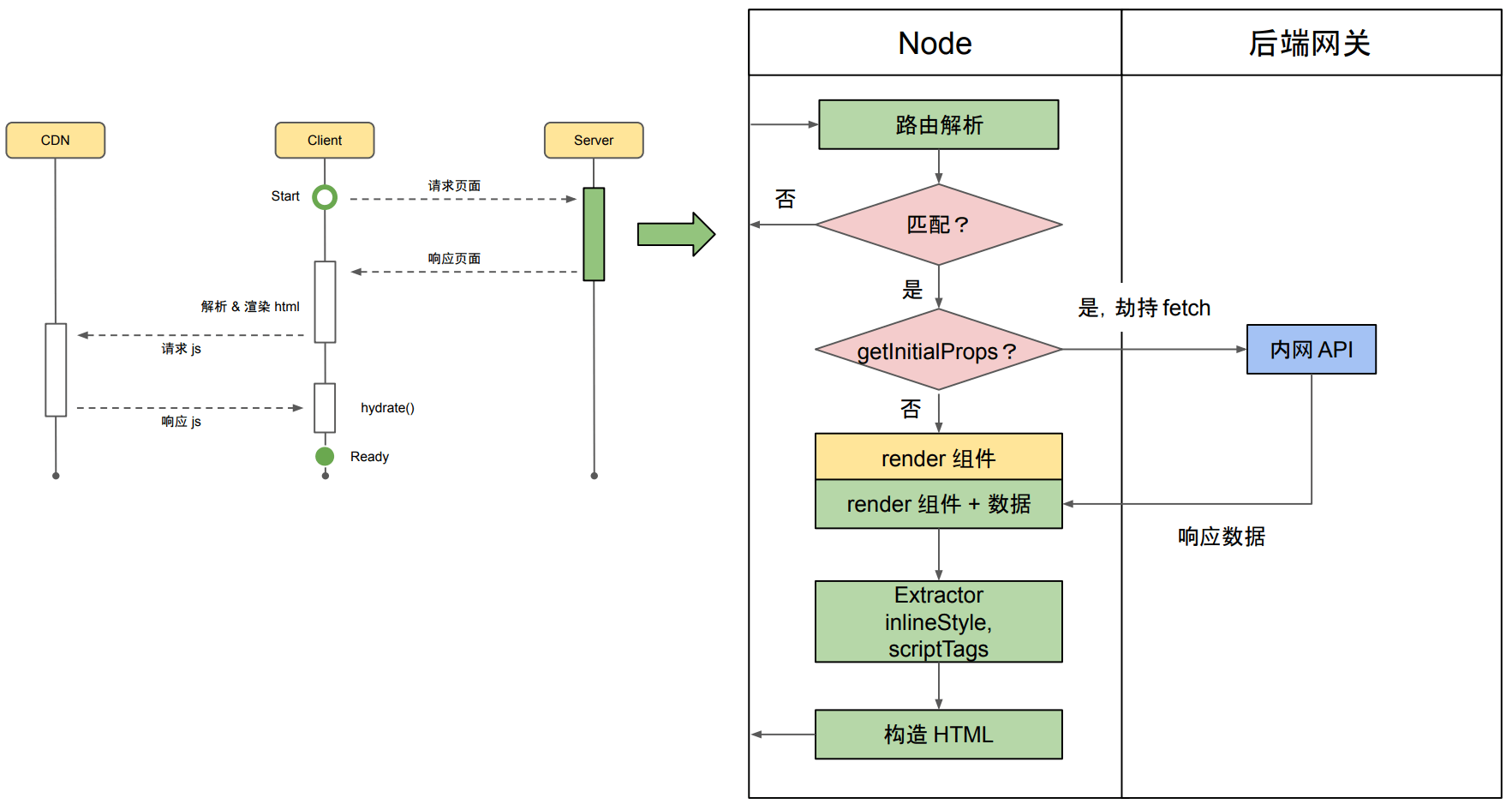
CSR 是成本最低,也最常见的。但是它天然存在一些问题,比如「白屏」,用户最初打开页面的时候,看到是一个几乎空白的 HTML。真正的内容要等到 CSS、JS 加载完成,运行并请求服务端接口,最后渲染出具体 DOM 结构。
这也就是 SSR 的优势。
3.1.1.1 SSR 的优势
优势1:LCP
首先是 LCP 问题,用户能在第一时间看到首屏页面,配合一些预加载等措施,LCP 问题能大大缓解。
优势2:CLS
同样的,由于首屏内容在服务端直接渲染好了,稍加注意,也大概率不会出现 CLS 问题。这些问题在 CSR 模式下都比较头疼。
3.1.1.2 SSR 的问题
SSR 解决了一些 CSR 的老问题,但是也带来了一些 CSR 没有的新问题。
问题1:FID 问题
首先是 FID 问题。
咱们从用户的角度想一想,打开页面就很快的看到了内容,那接下来呢?肯定是进行一些操作了对吧,但此时页面可能还在加载中��,或者 JS 正在运行中,用户的操作无法得到响应。
从技术角度考虑也是一样的,CSR 虽然在 LCP 上具有天然的劣势,有更长的白屏时间,但是在页面初始化时的 JS 解析执行、请求接口、渲染等操作都是比较「分散」的,而且在不同的异步任务中,反而一定程度上避免了「Long Task」的产生。SSR 则正好相反,在页面初始阶段需要密集的执行大量代码。
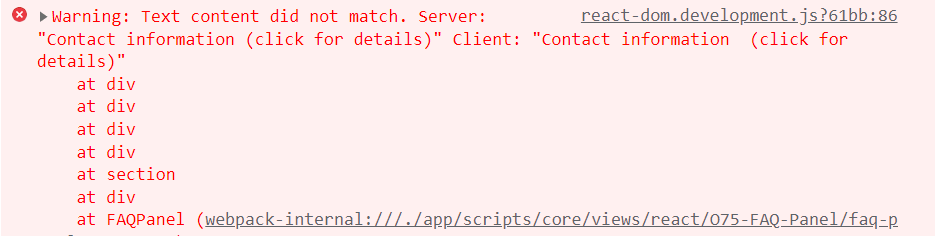
更坏的情况是,hydrate 异常降级为普通 render。这个还是比较容易发生的,我就遇到过非常多次:
- class 顺序不一致
- HTML 被意外压缩(没用的空格和换行)
- 海外不同时区,导致 Server 和 Client 计算的日期差一天
这种异常降级在 production 环境通常是静默的,表面上看没有影响用户的使用,但是对性能的损害却极大。而且排查起来比较繁琐。
问题2:强依赖接口性能
接下来是接口性能的问题。
先说明下,就像刚才的 SSR 流程图一样。我并不认为把代码在服务端 renderToString 就是所谓的服务端渲染,虽然我确实看到过这样做的。我理解的,和现在讲的 SSR,一定是包含必要数据的,渲染出的结果也基本能等同于用户看到的最终呈现(至少是首屏)。
所以数据是非常重要的,SSR 的效果会依赖服务端接口的性能。如果服务端接口迟迟不能响应,并且前端应用没有相应的超时和降级机制时,那么用户看到的只会「比白屏更白」。
在实践中遇到过少量:数据的实时性要求很高,因为其他种种原因而无法缓存,�平均响应时间大于 200ms 的接口。这种情况最好直接使用 SSG,再加上「骨架屏」之类的优雅点的 Loading。
问题3:无意义的 hydrate 和冗余代码
第三个问题是无意义的 hydrate 和冗余代码。
在日常开发中,总是会遇到一些静态,或者大部分区域是静态的页面。这些页面或区域,其实只需要服务端生成好 HTML,客户端渲染出来就可以了。hydrate 是完全没必要的,甚至 JS 都没必要加载,徒增负担。
除了客户端运行时的不必要负担,还增大了整个页面的体积,因为 JSX 里的内容会重复出现在 HTML 和 JS 里。
可以看到这张图片,HTML 和 JS 在都包含同样的代码。
实践中 JSX 的冗余其实还好,更可怕的是数据,最可怕是「不做处理,有用没用都返回的数据」。这些数据通常是内联在 HTML 中,保证客户端 hydrate 的时候可以第一时间拿到。对于动态内容为主的页面,SSR 数据占 HTML 体积 50% 以上也是常事。

问题4:架构的复杂度
第四个问题是,架构本身的复杂度。
SSR 其实并不是那么简单的,它的复杂度来自多个方面。
- 应用方面:需要确保稳定性,不管是守护进程还是容器伸缩,都要做好必要的保障。同时要能主动或者自动的降级。服务端渲染时要控制接口超时时间,没有超时降级机制,性能的损害反而是小事,更糟糕的情况是接口长时间无响应,导致页面也长时间无法响应,请求堆积在 node 层,直到崩溃,直到 502。
- 编码方面:需要一开始就做好规划,考虑清楚代码运行在服务端和客户端的各种情况,明确哪部分必须要 SSR,哪部分可以在客户端再执行,怎么设计才能达到最好的性能。SSR 的部分还要兼容降级的场景。此外,还需要设法兼容无法在 server 端执行的类库。
3.1.1.3. 实例对比
最后,咱们来看一个实例。我找来很久之前的一个活动项目,它本身是 SSR 的,单独拉了一个分支改造为 CSR,部署了两套一样的环境。
其他一些信息:
- 测试页面是活动项目,首屏没有动态数据,SSR 不涉及数据请求。
- 页面的埋点、异常监控、性能监控、指纹、加解密(JS 文件会大挺多)、eruda 等都保留着。
- 构建、部署流程调整起来比较麻烦,这次用的都是开发的配置,production 下的优化全没有。
- 主要技术栈就是 React 全家桶 + CSS Modules。
- 使用 Edge 的 devtools performance 测试,和 Chrome 差别不大。Edge 的本地化做的不错,而且我没有装任何扩展插件,不会产生干扰。
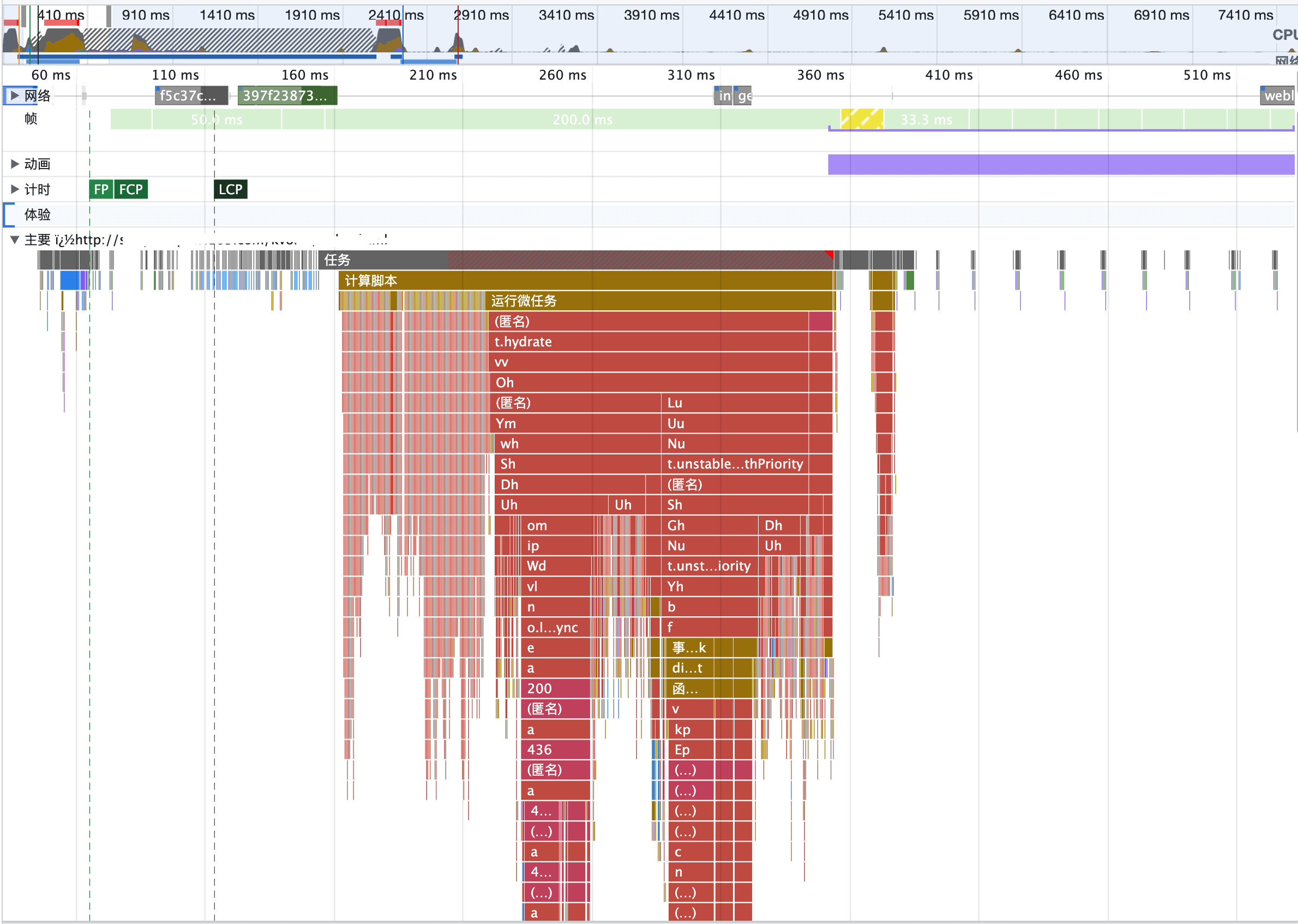
先看 SSR 的结果:
然后是 CSR 的结果:
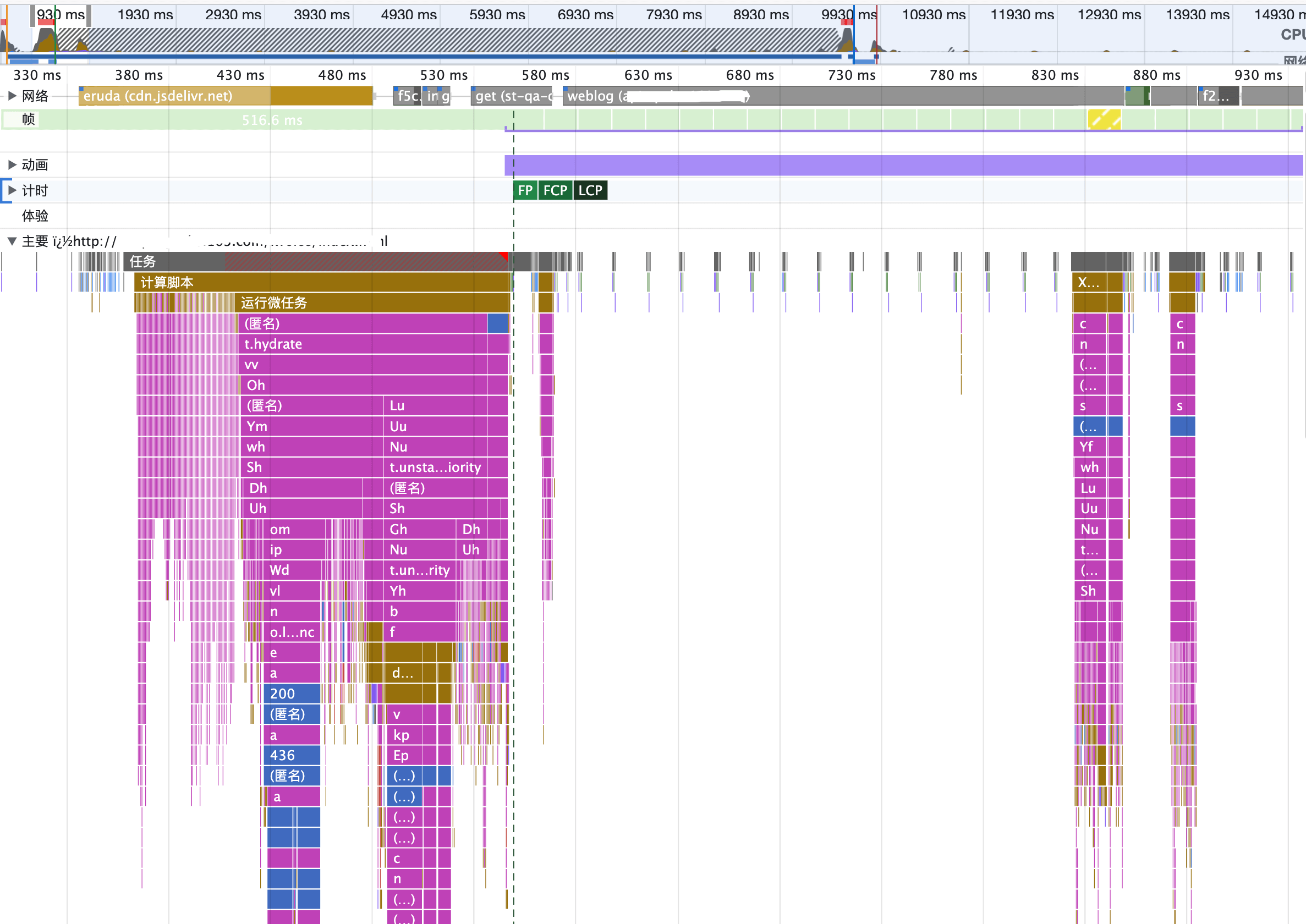
对比两份运行结果,可以得到这么几个关键信息:
- LCP 时长:SSR 120ms 左右,CSR 570ms 左右。即使不包含首屏数据的优化,LCP 上的优势还是很明显的。
- LCP 元素的渲染路径:SSR 在渲染前没有大段的 JS Task,而 CSR 需要等 JS 执行完。与我们前面的分析一致。
- Long Task:SSR 最长 199.71ms,而且比较集中;CSR 最长 188.96ms,分散成了 3 段。更糟糕的是 SSR 的长任务就在 LCP 元素渲染完成之后,非常容易阻塞用户的操作。
所以,总的来看,SSR 还是有明显优化效果的。
3.1.2 SSG#
刚才讲了很多的 SSR 相关内容,有优势,也有问题。不过,其实是有办法在一定程度上扬长避短的 —— SSG。
SSG 就是 Static Site Generation,不过我觉得,类比于 SSR,其实也可以叫 Server Side Generation,这样更好理解。
SSG 的核心其实很简单:就是「构建时的无数据 SSR」—— 在构建编译的时候,准确说是完成编译构建后,遍历全部路由,执行类似不带数据的 SSR,然后把生成的 HTML 保存下来。
SSG 有一些好处:
- 首先,它很简单,部署和运维方式都和 CSR(SPA)一致,无需考虑 SSR 的稳定性、降级等问题。
- 其次,它解决了 CSR 的 LCP 问题,和 SSR 类似,用户可以在第一时间看到首屏内容(不含数据)。
- 最后,SSG 不涉及数据,所以也不依赖服务端接口性能。非常适合比较简单的页面。如果是全动态数据的页面,需要考虑骨架屏等提升体验的交互方式,配合类似 SWR 的技术,可以做到类端体验。
不过 SSG 和 SSR 一样,都存在「FID」、「无意义的 hydrate」和「冗余代码」的问题。
但是总的来说,SSG 还是非常推荐的,低成本、高性能。
3.1.3 更多渲染模型#
SSR、SSG 并不是二选一的,我们再看一下刚才的 SSR 流程图:
这里的一个关键是 getInitialProps,通过它判断是否需要「数据预取」,如不需要,其实整个流程就是在服务端执行一下 renderToString 而已。
那么就很容易混用 SSR 和 SSG 了,构建时判断是否存在 getInitialProps,不存在执行预渲染。运行时判断是否存在getInitialProps,存在就走常规 SSR 流程,不准存在立即返回预构建产物,也就是 SSG。当然这个流程可以进一步优化。
混用 SSR 和 SSG 的好处是可以同时兼顾高度动态化的页面和偏静态的页面。
另外,其他的「渲染模型」变种也特别多,多到了只要把握精髓,活学活用,就可以任意组合使用。
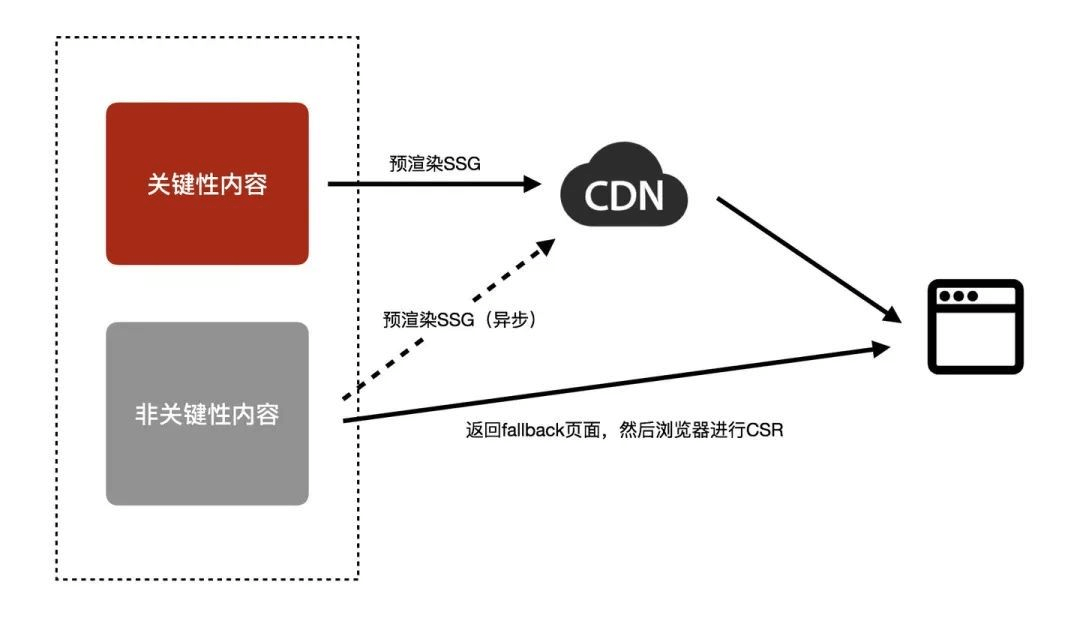
比如 ISR —— 增量式站点渲染:
- 关键性的页面(如网站首页、热点数据等)预渲染为静态页面,缓存至 CDN,保证最佳的访问性能;
- 非关键性的页面(如流量很少的老旧内容)先响应 fallback 内容,然后浏览器渲染(CSR)为实际数据;同时对页面进行异步预渲染,之后缓存至 CDN,提升后续用户访问的性能。
3.1.4 Suspense SSR Architecture#
上面讲的 SSR 和 SSG,一定程度上解决了 CLS 和 LCP 问题。但是依然存在 FID 问题,还引入了一些其他的问题。那么有办法彻底解决吗?
2022 年 3 月,React 正式发布了 v18.0.0,带来了新的 Suspense SSR Architecture,以提高 SSR 性能。
功能层面,React 18 引入了两个重要的能力:
- Streaming HTML
- Selective Hydration
咱们通过一个实例看下这两个新功能:
const UserInfo = React.lazy(() => import('./UserInfo.js'))
const Explore = React.lazy(() => import('./Explore.js'))
// ...
const App = (
<Layout>
{/* 视频播放器 */}
<VideoPlayer />
{/* 作者信息 */}
<Suspense fallback={<UserInfoSkeleton />}>
<UserInfo />
</Suspense>
{/* 更多推荐视频 */}
<Suspense fallback={<ExploreSkeleton />}>
<Explore />
</Suspense>
</Layout>
)
这是一个「视频作品页面」,结构很简单,分三个部分:频播放器、作者信息、更多推荐视频。
3.1.4.1 Streaming HTML
Streaming HTML,就是服务端流式 HTML。服务端能尽早响应 HTML,后续,其他的 HTML 片段附带 script 一起流式传输给客户端,script 执行将 HTML 插入到正确的位置。
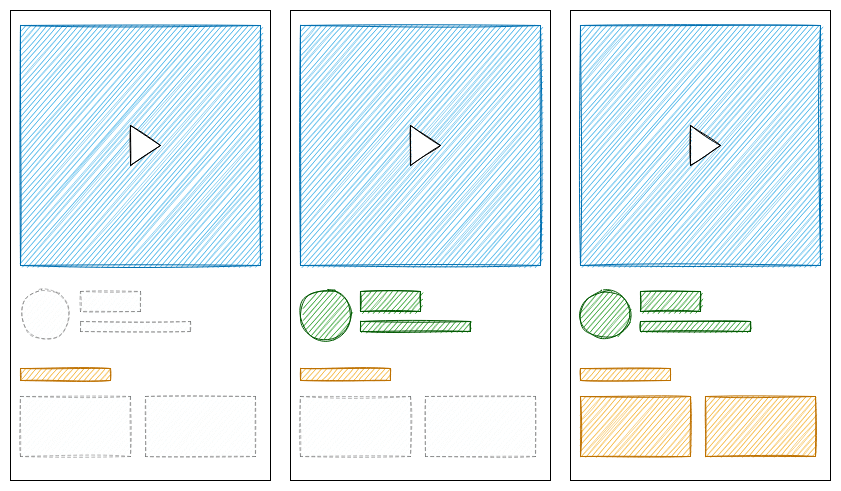
(说明:“虚线框” 代表占位的 Skeleton;“彩色实线框” 代表真实的 HTML)
Streaming HTML 很好的解决了服务端渲染页面时,对接口响应速度的过度依赖。加载比较慢的组件,不会影响到较快的部分。
3.1.4.2 Selective Hydration
Streaming HTML 解决了「服务端」上的一些问题,比如强依赖服务端接口性能,那么「客户端」运行时的问题,还要看 Selective Hydration。
前面提到过 FID 问题,因为 SSR 的 hydrate 需要一次性处理完整个页面,这个过程可能耗时比较长,极容易产生 Long Task,阻塞客户端对用户操作的响应。之前缓解此类问题的方案是把一部分组件通过 Code Splitting 拆分出去,在客户端异步的 CSR,说白了就是部分的放弃 SSR。
而在 React 18 中,React.lazy 支持了服务端渲染,可组合使用 React.lazy 和 <Suspense>。就像上面示例的 <UserInfo /> 和 <Explore />,它们的 JS 加载和 hydrate 都是独立的,互不影响。Selective Hydration 机制打破了之前一次性水合的限制,我们可以根据需求灵活的控制,同时享受 SSR、Code Splitting 和独立的 hydrate,三倍的快乐。
还不仅如此,Selective Hydration 真正的大杀器,其实是基于用户交互的优先级调度。在 React 18 里,<Suspense> 内执行 hydrate 时,会有极小的间隙来响应用户事件
还是刚才的例子:
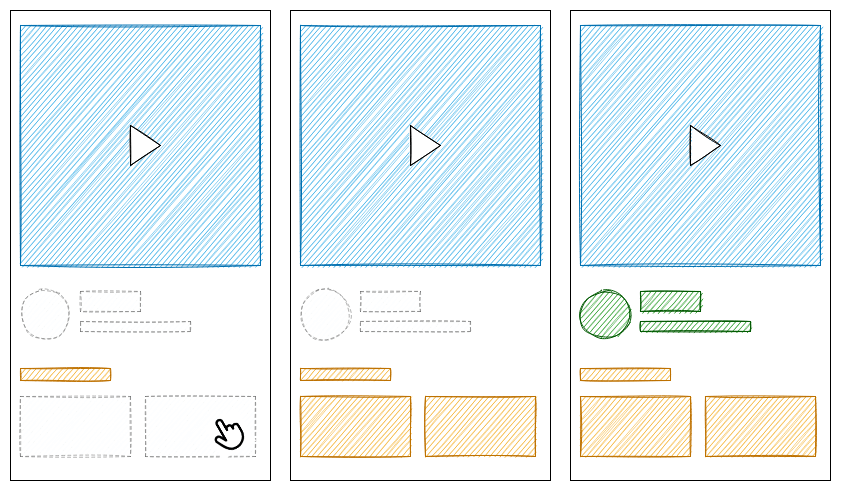
(说明:“虚线框” 代表未完成 hydrate 的区块,还无法响应用户的交互;“彩色实线框” 代表可交互的区块)
最左侧的图,此时 <UserInfo /> 和 <Explore /> 都还未 hydrate,无法响应用户的交互。用户点击 <Explore /> 组件,React 会认为它是更重要更紧急的部分,在 click 事件的捕获阶段,同步完成 hydrate,然后响应用户的点击。
3.1.5 Islands Architecture#
Suspense SSR Architecture 依然是基于 React 架构下的解决方案,可以缓解 FID 问题,但是还是不够不彻底。使用 Streaming HTML 的成本也是很高的。
那么......还有没有更好的办法呢?咱们来重新捋一下思路。
SSR 可以直接在服务端渲染好页面(一般是首屏),这很好,可以一定程度上解决 LCP 和 CLS 问题。
但是要等待加载并运行好 JS,才能响应用户的交互。这就有问题了,JS 集中执行,同时还存在无意义的 hydrate 和冗余代码。这非常不利于 FID。React 的 Suspense SSR Architecture 尝试通过「流式 HTML」和「选择性 hydrate」解决,其实还有更直接的方法,就是 —— Islands Architecture。
3.1.5.1 基础概念和原理
Islands Architecture,可以叫做「岛屿架构」、「岛屿模型」都行。
它的核心思想是把页面分为动态部分和静态部分,静态的部分就像 SSR 或者 SSG 一样渲染出来,但是在服务端生成 HTML 后,在客户端渲染时不带任何 JS 代码。
动态的部分,服务端渲染出的 HTML 将包括动态内容的占位符。动态内容占位符包含独立的组件小部件。每个小部件都类似于一个应用程序,包含服务器渲染的输出、和用于在客户端 hydrate 应用程序的 JavaScript。每个动态组件,都好比一座座 island,互不影响,独立运行。
Islands Architecture 通过页面的合理拆分,保证静态部分只是纯静态代码,不包含任何 JS,以达到减少无意义的 hydrate,减少 JS �代码量。
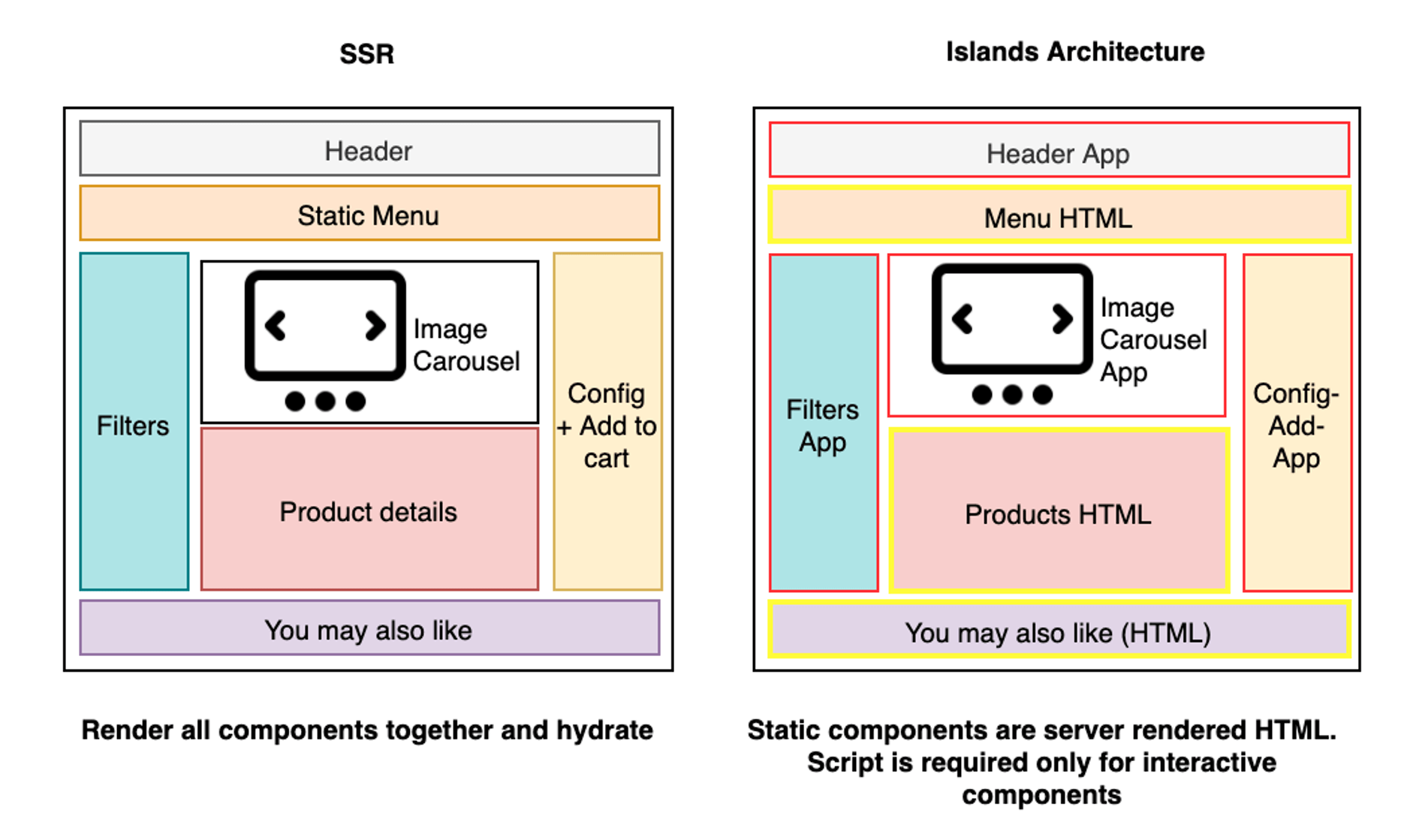
图片的解释
- 左侧:经典的 SSR,所有组件同时 render + hydrate
- 右侧:Islands Architecture,静态部分服务端渲染,仅加载可交互式组件的 JS(并且每部分都是独立的)
3.1.5.2 框架支持
目前有很多框架都实现了 Islands Architecture:

Marko 是一个开源框架,由 eBay 开发和维护,用于提高服务端渲染的性能。它通过流式渲染(streaming rendering)与自动部分 hydrate 相结合,来支持 Islands architecture。HTML 和其他静态资源,一旦准备好就会立刻流式传输到客户端。交互式组件可以独立、自行完成 hydrate。hydrate 代码仅用于交互式组件,它可以更改浏览器上的 state。它是同构的,Marko 编译器会根据运行位置(客户端、服务器)生成优化后的代码。

Astro 是一个静态站点生成工具,可以使用其他框架(如 React、Preact、Svelte、Vue 等)构建的 UI 组件,生成轻量级的静态 HTML 页面。需要客户端 JavaScript ��代码的组件会单独加载它们的依赖项。因此,它提供了内置的部分 hydrate。

还有 Fresh,使用 Preact 框架实现,天然就是基于 Island 的客户端 hydrate 方案。如果页面不含动态部分,那么运行时的开销是零,不含任何 JS 代码。
3.1.5.3 Fresh 实例
接下来咱们就看个 Fresh 实例:
// routes/index.tsx
import Counter from '../islands/Counter.tsx'
export default function Home() {
return (
<div>
<p>
Welcome to Fresh. Try to update this
message in the ./routes/index.tsx file,
and refresh.
</p>
<Counter start={3} />
</div>
)
}
// islands/Counter.tsx
import { useState } from 'preact/hooks'
import { IS_BROWSER } from '$fresh/runtime.ts'
interface CounterProps {
start: number
}
export default function Counter(props: CounterProps) {
const [count, setCount] = useState(props.start)
return (
<div>
<p>{count}</p>
{/* 这个 disabled 可以说很细节了 */}
<button onClick={() => setCount(count - 1)} disabled={!IS_BROWSER}>
-1
</button>
<button onClick={() => setCount(count + 1)} disabled={!IS_BROWSER}>
+1
</button>
</div>
)
}
运行效果:
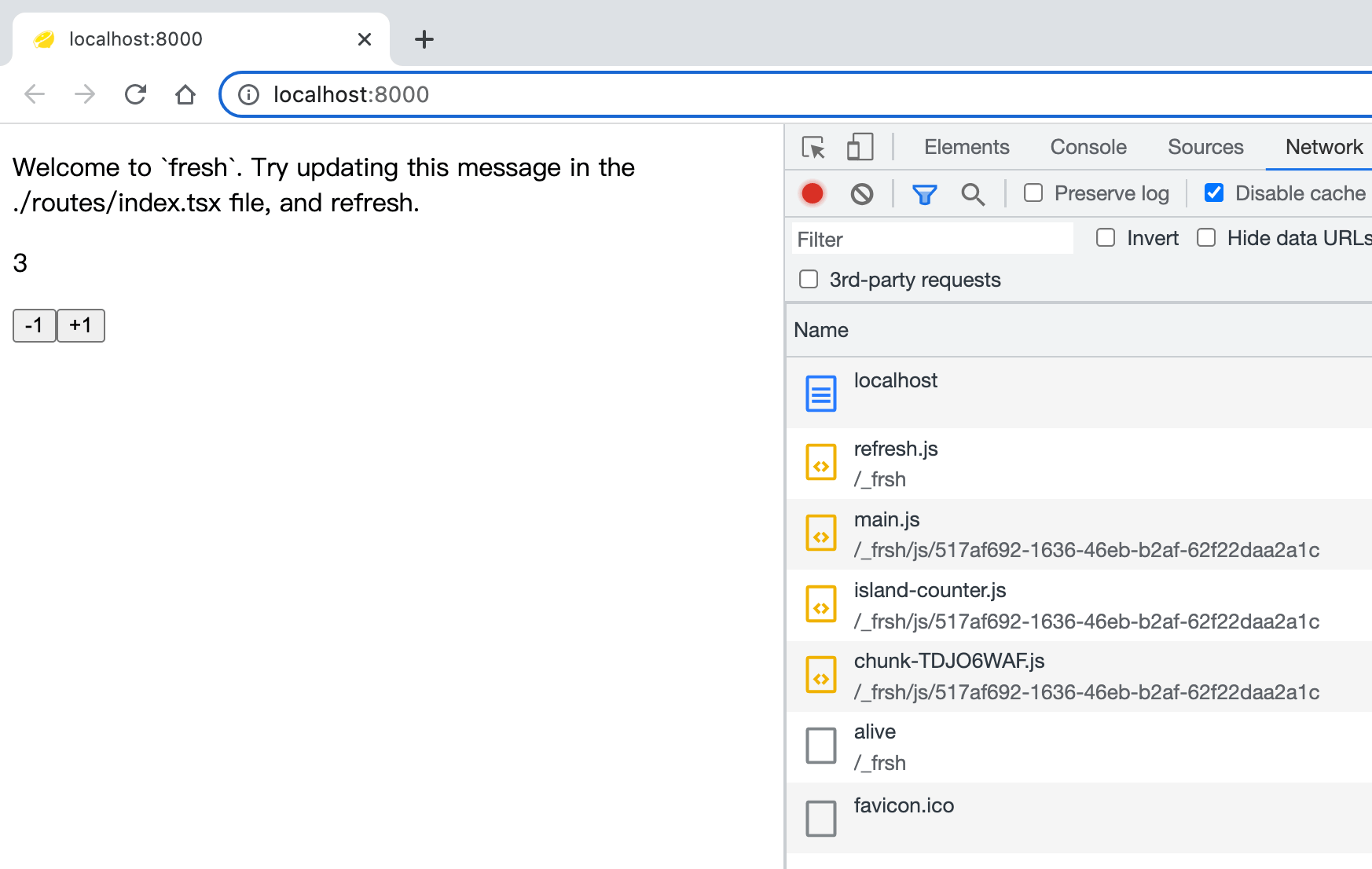
可以看到,客户端加载的 JS 代码很少:
main.js和chunk-TDJO6WAF.js主要是 Fresh 的 runtime 代码和 preactisland-counter.js就是的 Island 组件
后续如果添加更多的可交互组件,也会类似 island-counter.js 一样,独立为一个个互不影响的 island。
Fresh 内部强依赖 Preact,通过 Preact 将所有组件渲染为 HTML,给 Islands 打好标记。同时 JS 的依赖收集根据约定的目录控制好范围。在客户端,使用少量运行时和 Preact,完成 hydrate。下面是 SSR 生成的 HTML 片段:
<div>
<p>Welcome to `fresh`. Try updating this message in the ./routes/index.tsx file, and refresh.</p>
<!--frsh-counter:0-->
<div>
<p>3</p>
<button disabled>-1</button>
<button disabled>+1</button>
</div>
</!--frsh-counter:0-->
</div>
3.2 离线包#
刚刚聊了很多前端架构的问题,不过在最开头讲「系统级优化」的时候也提到过了,前端性能不仅仅局限在前端的范围内,还需要与服务端和客户端紧密配合,而「离线包」就是这样的典型场景。
离线包的一般定义是这样的:一个包含 HTML、JavaScript、CSS、图片等静态资源的压缩包。APP 预先下载离线包到本地,拦截 webview 的请求并使用本地资源响应,从而最大程度地摆脱网络环境对 H5 页面的影响。
粗看定义,其实解决的也就是网络问题,不过如果彻底解决加载问题,对用户体验的提升还是非常大的。但是围绕「离线包」这个点,可做的事情非常多,比如:
- 差量更新(增量更新):前端应用部署�后,APP 可直接通过差量包更新,无需每次下载全量包。
- 接口预请求:可以在配置文件内定义好接口,APP 在初始化 webview 的同时,会预请求接口,保证 H5 能更快的拿到数据。
- 公共三方库
- 多语言适配
- 强制更新
- 动态离线
- 容器预热
当然了,离线包其实也存在一些弊端:
- 侵入性大:需要接入 Android 和 iOS 的 SDK,对现有 APP 的侵入较大。还比较容易出 bug,之前遇到过离线包导致正常图片的
cache-control失效 - 支持的平台少:传统方案通常只支持 Android 和 iOS。无法支持 web 端(PC、H5),如桌面浏览器,分享到其他 APP 的 H5 链接。
- 开发成本高、复杂度高:需要 Android、iOS 分别支持,具体的策略需要双端对齐,更新和迭代需要双端开发。同时需要服务端开发对应的离线包更新和分发服务。
- 灵活性低:表现在两方面,一是任何功能的迭代,需要双端发布版本;二是策略上比较固定,前端(JS)的可操作空间小。
- 非标准化:大家实现的方案思路大体一致,但是功能、API等细节千奇百怪。
但是总体上看,设计一套强大的离线包方案,对前端性能提升还是大有裨益的,特别面对海外的复杂网络情况。
3.3 Service Worker#
离线包虽然好用,但是成本大,需要客户端和服务端配合。特别是非 APP 内的环境,离线包就不起作用了,这时候,其实可以使用 Service Worker 达到类似的效果。
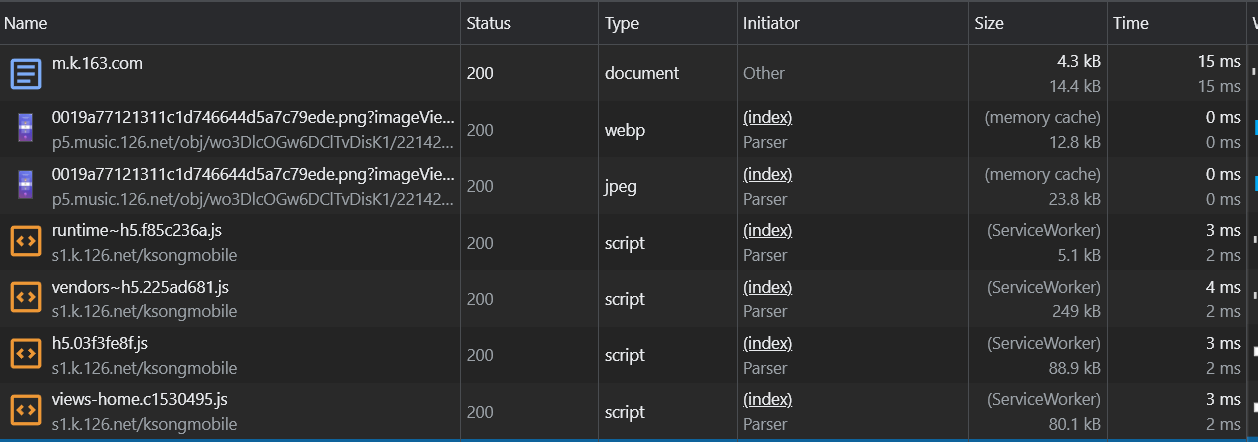
Service Worker 就不存在离线包的那些问题,它最大的问题是首次访问无效:
- 「侵入性大」的问题:Service Worker 仅需接入前端 SDK,本身对前端代码的侵入性极低,对其他端无侵入性,接入简单。
- 「支持平台少」的问题:这个主要取决于容器对 Service Worker 的支持。目前大部分设备是支持的。iOS 可能要稍加改造。
- 「针对成本高、复杂度高」的问题:Service Worker 无需服务端开发,无需复杂的离线包版本、更新、差量计算、下载等服务。
- 「灵活性低」的问题:这个就更不存在了,可配置缓存命中策略,更新策略。具有极高的灵活性。
- 「非标准化」的问题:天然不存在。
Service Worker 的灵活性非常高,通常并不会直接使用底层 API,而是基于 google 开源的 Workbox 来定制策略。

这里拿之前「音街」项目来分享下,具体流程是这样的:
首先,在构建时收集需要预缓存的资源�,分两种映射表和索引。
- 索引用来预缓存资源
- 映射表,配合
sw.js的较短缓存时间,可以保证 HTML 即使缓存更新不成功,也能匹配失败,转为在线模式。
// 映射表
{
"path.html": "path.h836dj35.html",
"guide.html": "guide.83isyrn6.html"
}
// 索引
[
'path.h836dj35.html',
'guide.83isyrn6.html',
'path.e949269d3.js',
'dress-up-center.69250f468.js',
'dress-up-center.kdjf3ueyw.css',
'rank-outer-room-rank.c0ar8c007.js',
'rank-inner-room-rank.d4d544da8.js',
]
代码的入口处,安装 Service Worker
const registerSw = () => {
if (typeof window === 'undefined') {
return;
}
const register = async () => {
// 不支持 sw,直接退出
if (!('serviceWorker' in navigator)) {
log('sw-notsupport');
return;
}
try {
await navigator.serviceWorker.register('sw.js');
log('sw-success');
} catch (error) {
log('sw-error', error);
}
};
if (/loaded|complete/.test(document.readyState)) {
register();
} else {
window.addEventListener('load', register);
}
};
export default registerSw;
安装完成后,具体的策略就写在 sw.js 内。比如,直接下载全部的需要预缓存的资源(就是前面的索引)
// 预缓存资源
precacheAndRoute(PRECACHES_FILE_LIST, {
directoryIndex: null,
urlManipulation: ({ url }) => {
const pathname = url.pathname;
if (routeToCachePath[pathname]) {
return [new URL(`${routeToCachePath[pathname]}`, location.href)];
}
return [url];
},
});
另外也可以动态缓存一些图片
// 静态资源图片缓存
registerRoute(
({ request, url }) => request.destination === 'image' && url.href.indexOf(PUBLIC_PATH) > -1,
new CacheFirst({
cacheName: 'static-images',
plugins: [
new CacheableResponsePlugin({
statuses: [0, 200],
}),
new ExpirationPlugin({
maxEntries: 1000,
maxAgeSeconds: 60 * 60 * 24 * 30, // 30 Days
}),
],
})
);
Workbox 功能非常强大,如果对 Service Worker 有兴趣的话,可以好好研究下。
iOS 端的特殊处理
1、在工程的 Info.plist 文件中,新增 WKAppBoundDomains 配置项,填写需要开启 Service Worker 的域名列表

2、构造 WKWebView 实例时,传入的 WKWebViewConfiguration 参数需要开启 App Bound
WKWebViewConfiguration *config = [WKWebViewConfiguration new]; config.limitsNavigationsToAppBoundDomains = YES; WKWebView *webview = [[WKWebView alloc] initWithFrame:CGRectZero configuration:config];
3.4 库和组件#
3.4.1 高内聚的业务组件库#
这个就简单的提一下,面向 C 端的组件通常都是业务内自己积累的,极少场景能直接使用类似 antd 的组件库。曾经遇到过一些项目,组件都比较凌乱,没有经过合理、系统化的规划。比如手势库,Swiper 组件用一个�,Tab 组件用一个。再比如日期库,有的地方是自己写的,有的地方是 date-fns 或者 Day.js。
对于前端(特别是 C 端 H5),控制代码体积是很重要,也很头疼的部分。JS 代码中三方库占据很大的比例,所以一套适合自己业务的高质量、高可维护、高内聚的业务组件库,和架构选型一样重要,是高性能应用的基础。
- 底层:日志、Bridge、异常处理、视口检测、环境检测 ...
- 中层:Lazyload、列表、日期、手势 ...
- 上层:LazyloadImage、下拉刷新、用户列表、Swiper、Tab ...
3.4.2 三方库的选择#
几个建议:
- 注意代码体积:比如 recoil,它是基于 es5 的数据层方案,比较重,h5 场景可以考虑用 zustand、jotai 替代
- 注意 tree shaking:即使只使用其中一部分,也要验证是否能 tree shaking。lodash 不用多说了,此外还看到过为了 datepicker 而引入几乎整个 antd 的项目
- 注意 code splitting:一些刚需的三方库,比如 html2canvas,结合需求,考虑
import()
4. 面向 web vitals 的优化实践#
接下来咱们聊一些更加具体的优化手段和技巧,是日常写代码的过程中,需要注意的点。
4.1 关键渲染路径优化#
首先是关键渲染路径的优化。
按照 MDN 的定义,关键渲染路径是浏览器将 HTML,CSS 和 JavaScript 转换为屏幕上的像素所经历的步骤序列。优化关键渲染路径可提高渲染性能。关键渲染路径包含了 文档对象模型(DOM),CSS 对象模型 (CSSOM),渲染树和布局。
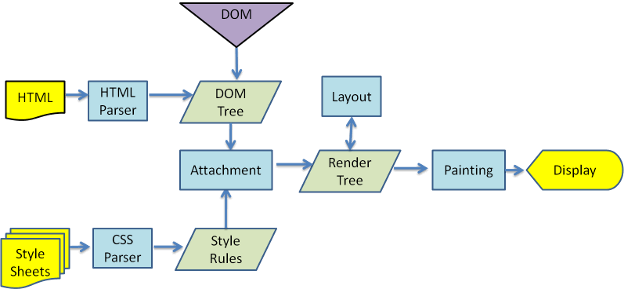
这个概念可大可小,一般来说,现在页面的内容大多时候只要 HTML 和 CSS 即可完成渲染,特别是 SSR 和 SSG 等模式下。这些咱们刚刚讲过,在服务端即可渲染出 HTML 结构,但仅有 HTML 是不够的,还需要把相关的 CSS 也预先插入在页面上。
原理是相通的,这里以 loadable-component 为例说明:
import { renderToString } from 'react-dom/server'
import { ChunkExtractor } from '@loadable/server'
const statsFile = path.resolve('../dist/loadable-stats.json')
const extractor = new ChunkExtractor({ statsFile })
// SSR html
const html = renderToString(extractor.collectChunks(<YourApp />))
// CSS
const styleTags = await extractor.getInlineStyleTags();
// JS
const scriptTags = extractor.getScriptTags();
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<% if (typeof styleTags !== 'undefined') { %>
<%- styleTags %>
<% } %>
</head>
<body>
<% if (typeof body !== 'undefined') { %>
<div id="root"><%- body %></div>
<% } %>
<% if (typeof scriptTags !== 'undefined') { %>
<%- scriptTags %>
<% } %>
</body>
</html>
它可以在 SSR renderToString 的时候,结合 webpack 的 stats.json,提取 JS 和 CSS。我们只需将提取到的相应代码,插入到模板对应的位置,这样 HTML 文件加载完毕,可以直接渲染出页面了。
4.2 资源加载优先级#
4.2.1 保证 LCP 元素第一优先级加载#
一般 LCP 元素都是图片,我们要保证图片紧跟在 HTML 请求后,第一优先级级加载
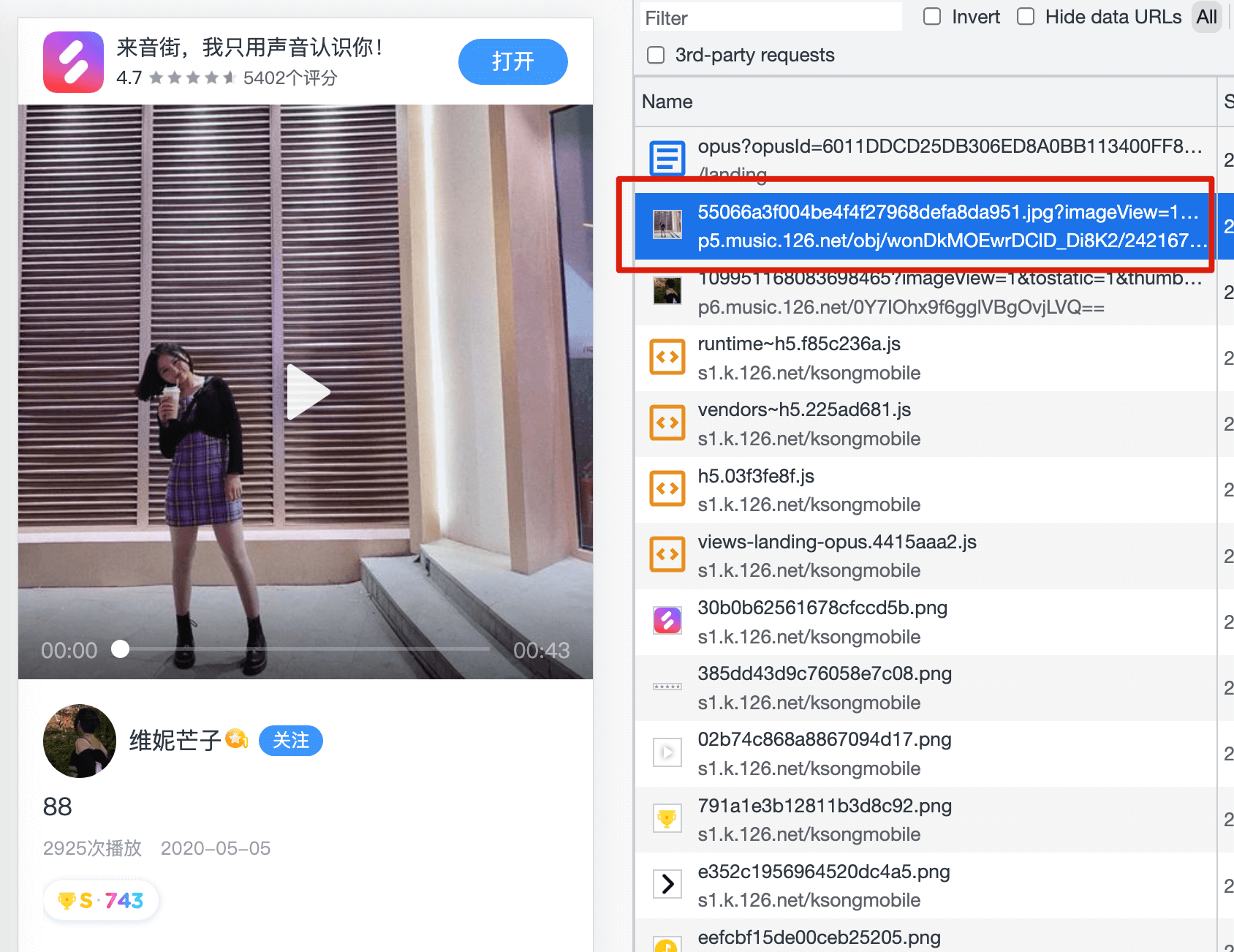
常规的做法有两种:
- 如果 HTML 结构比较合理的话,保证使用
<img />标签即可,<img />的优先级高于background-image - 如果 HTML 结构混乱、或者比较复杂,可以考虑使用 preload
<link href="//p5.music.126.net/image.png" rel="preload" as="image">
4.2.2 延迟加载低优先级资源#
分两种情况,首先是图片,非 LCP 元素图片、或者其他不重要的图片,全部要 Lazyload
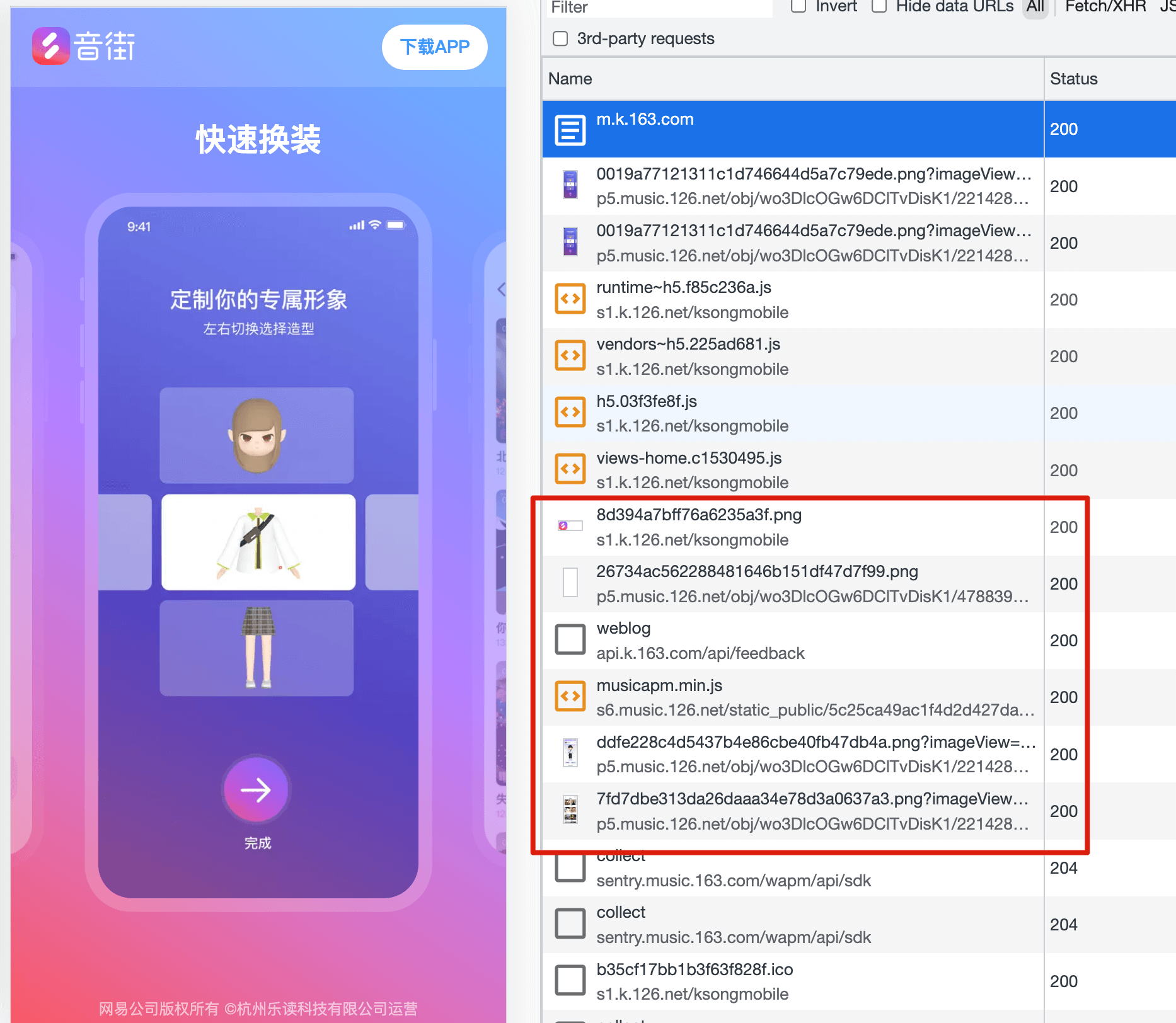
他们要晚于 JS 文件加载,这样才是一个比较合理的优��先级。
其次是:页面的其他部分,整体延迟加载,比如视口之外的部分,不可见的路由、Tab 等。举个例子:
useEffect(() => {
// 延迟加载页面的评论
timer = window.setTimeout(() => {
insertGiscusScript()
}, 80)
return () => {
window.clearTimeout(timer)
const $giscusContainer = document.querySelector('.giscus')
const $giscusScript = document.querySelector('#giscus-script')
if ($giscusContainer != null) {
$giscusContainer.innerHTML = ''
}
if ($giscusScript != null) {
$giscusScript.remove()
}
}
}, [])
整体上看,资源的加载优先级,应该按照这样的顺序:
- LCP 元素和重要的图片
- 页面的 JS(关键渲染路径优化已将 CSS 内联)
- 其他的图片,功能模块
- 不可见的部分,基于条件加载
- 视口之外的模块:可基于视口的变化加载
- 路由,标签页:基于用户的操作加载(可适当预加载部分内容)
4.3 图片格式#
图片格式也是在日常开发中,经常出现问题的一个点。这里主要聊两点内容。
4.3.1 优先使用新格式#
第一是优先使用比较新格式,通常 webp 或者 avif 体积都更小。
一些小图标,经常用 png 格式,这个影响其实不是特别大,用不用都行。但是背景图、照片、封面等都应该尽量使用新的图片格式。
目前一些比较有名的 CDN 或媒体服务,都支持「自动选择图片」,比如 imgix:

如果你使用的图片服务刚好不支持,比如网易的 NOS,那么可以考虑用 <picture> 标签:
<picture> <source srcset="photo.avif" type="image/avif" /> <source srcset="photo.webp" type="image/webp" /> <img src="photo.jpg" alt="photo" /> </picture>
<picture> 标签的弊端是,需要运行时浏览器自动判断,这样没法使用 preload 的方式预加载。所以要权衡下,LCP 元素的加载优先级、图片体积&格式等几个因素,都试试看。
但是!!!但是!!!无论如何都不要使用 JS 运行时判断,至于原因,大家可以思考下「关键渲染路径」的问题,捋一捋 LCP 图片的关键渲染路径。
// bad case
const getImgUrl = (img) => {
const suffix = `?imageView&thumbnail=390x0&quality=75&tostatic=0${
window.ACTSDK.Env.webp ? '&type=webp' : ''
}`;
return img.url + suffix;
};
4.3.2 正确使用 png 和 jpg#
实际开发中,可能总会有一些特殊的场景,是无法使用 webp 和 avif 的,比如因为某些原因,需要 preload 图片。那么此时,就要正确选择 png 和 jpg 了。
之前见到过一些项目,全部无脑使用 png。对 png 和 jpg 的认识,也仅仅停留在 png 支持透明。实际上远远不止这些。
jpg 和 png 最大的差别,其实是在压缩方式上,这个也��是对体积影响最大,对性能影响最大的地方。
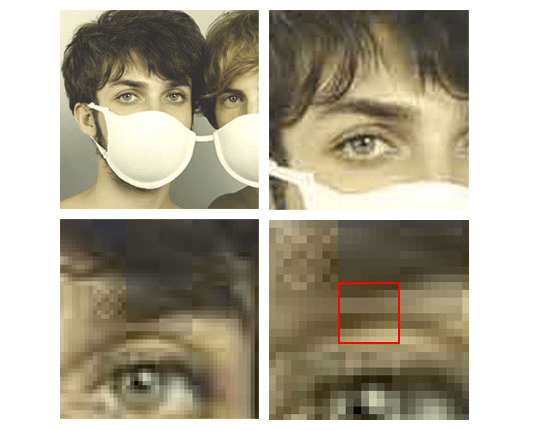
首先是 jpg,jpg 是我们最常见的,采用「有损压缩」对图像信息进行处理的图片格式。jpg 在存储图像时,会把图像分解成 8x8 像素的栅格,然后对每个栅格的数据进行压缩处理,当我们放大一幅图像的时候,就会发现这些 8x8 像素栅格中很多细节信息被去除,而通过一些特殊算法用附近的颜色进行填充。这也是为什么我们用 jpg 存储图像有时会产生块状模糊的原因。
而 png,是我们最常见的一种采用「无损压缩」的图片格式。无损压缩在存储图像前,会先判断图像上哪些地方是相同的,哪些地方是不同的,为此需要对图像上所有出现的颜色进行索引,我们把称这些颜色称为索引色。索引色就好比绘制这幅图像的「调色版」,png 在显示图像的时候则会用「调色版」上的这些颜色去填充相应的位置。

所以,在我们了解了「有损压缩」和「无损压缩」的具体原理后,就比较容易判断了。通常来说:色彩比较丰富的,比如真实的照片,带渐变色的图片,有很多阴影的图片,因为索引色非常多,就比较适合 jpg。相反,视觉直接画的小图标,简单的图片,就比较适合 png。
看一些实例:
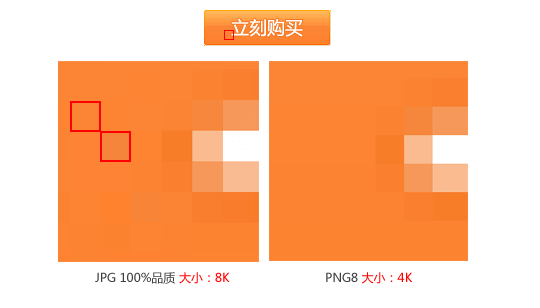
这是个常见的「购买按钮」,根据前面我们介绍的无损压缩的特性,当用 png 存储这个图像时,只需要保存很少的色彩信息就可以真实还原这个图像。而对于 jpg 格式来说大小主要决定于图像的颜色层次,所以在这种颜色较少但对比强烈的情况下,反而不能很好的压缩文件大小。
不过在实际开发过程中,我们的图片素材很少是 jpg 格式的,大多数情况下,都是「该用 jpg 但是没用」,导致图片过大,很少反过来。

比如这张背景,默认从视觉稿导出是 png 是 48.4 KB,但是转为 jpg 就只有 9 KB。
4.3.3 其他#
关于图片还有很多优化手段,压缩、Base64、雪碧图等等,已经讨论的比较多了,这里就不多聊了。
4.4 合理的拆分代码#
目前前端最常用的构建工具就是 webpack,但是 webpack 的 code splitting 插件 SplitChunksPlugin,用起来挺麻烦的。
比如目前比较常见的策略是:
- 全部
node_modules打包到 vendor 中 - 当某个库被多个页面引用的时候,��合并
/**
* SplitChunksPlugin 的默认配置
*/
module.exports = {
optimization: {
splitChunks: {
chunks: 'async',
minSize: 20000,
minRemainingSize: 0,
minChunks: 1,
maxAsyncRequests: 30,
maxInitialRequests: 30,
enforceSizeThreshold: 50000,
cacheGroups: {
defaultVendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10,
reuseExistingChunk: true,
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true,
},
},
},
},
};
这样其实一些极简单的页面,可能反而会加载很多没必要的代码。
这里举个实际的例子,一个大概有 50 个页面的 SSR 应用,根据页面的使用场景做了个多入口拆分(entry),分为「APP 内部的 H5」和「站外的分享落地页」:
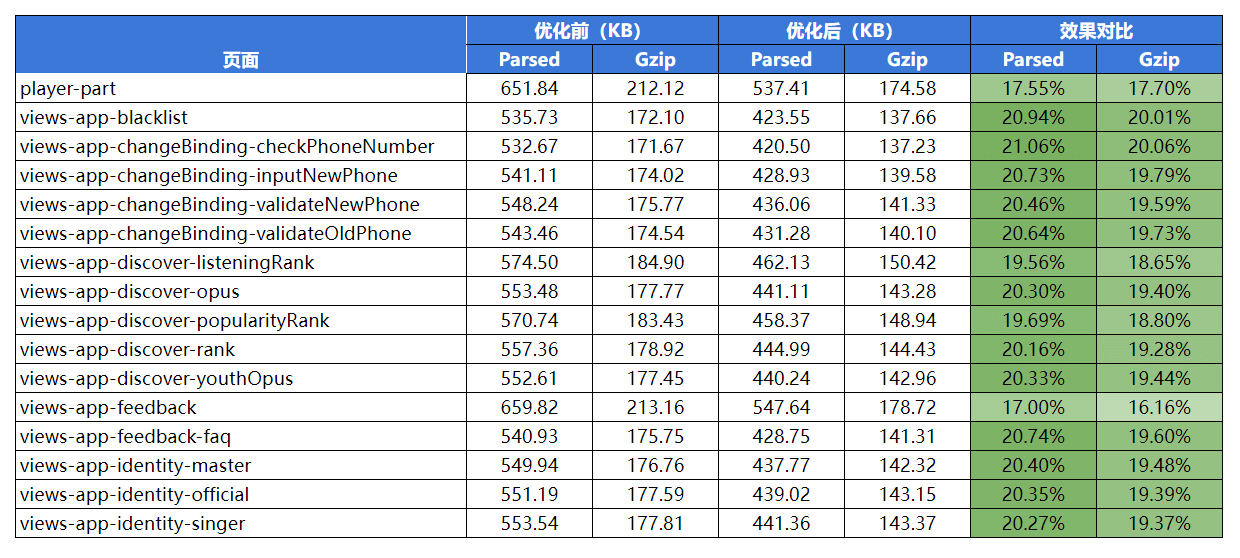
效果还是比较明显的。
但是具体怎么配置算最优呢?其实没有一个标准答案。需要具体问题具体分析,这里主要是给大家提供一个优化思路。
4.5 Yield Point#
FID 优化的关键之一,就是避免长任务(Long Task),尽可能的将长任务拆分为若干个小的任务,使得浏览器可以响应用户操作等高优先级的事情。而任务的拆分,最简单粗暴的方式就是使用 setTimeout 等 MacroTask,比如:
useEffect(() => {
// 性能监控
if (process.env.NODE_ENV === 'production') {
setTimeout(initWapm, 0);
}
// 注册 Service Worker
if (process.env.NODE_ENV !== 'development') {
setTimeout(registerSw, 0);
}
}, []);
前段时间,我在 web.dev 看到一个新词汇:Yield Points 。其实它的本质还是 setTimeout,但是实现的很优雅、很美。
function yieldToMain() {
return new Promise((resolve) => {
setTimeout(resolve, 0)
})
}
我们看个具体的实例:
function fun() {
let total = 0
for (let i = 0; i < 20000000; i++) {
total = total + i
}
console.log(total)
}
async function run() {
const fun1 = () => fun()
const fun2 = () => fun()
const fun3 = () => fun()
const fun4 = () => fun()
const fun5 = () => fun()
const tasks = [fun1, fun2, fun3, fun4, fun5]
while (tasks.length > 0) {
const task = tasks.shift()
task()
}
}
run()
这是它的运行火焰图:

我们使用 Yield Point 稍加改动:
//...
while (tasks.length > 0) {
const task = tasks.shift()
task()
// 只添加了这一行 !!!
await yieldToMain()
}
//...
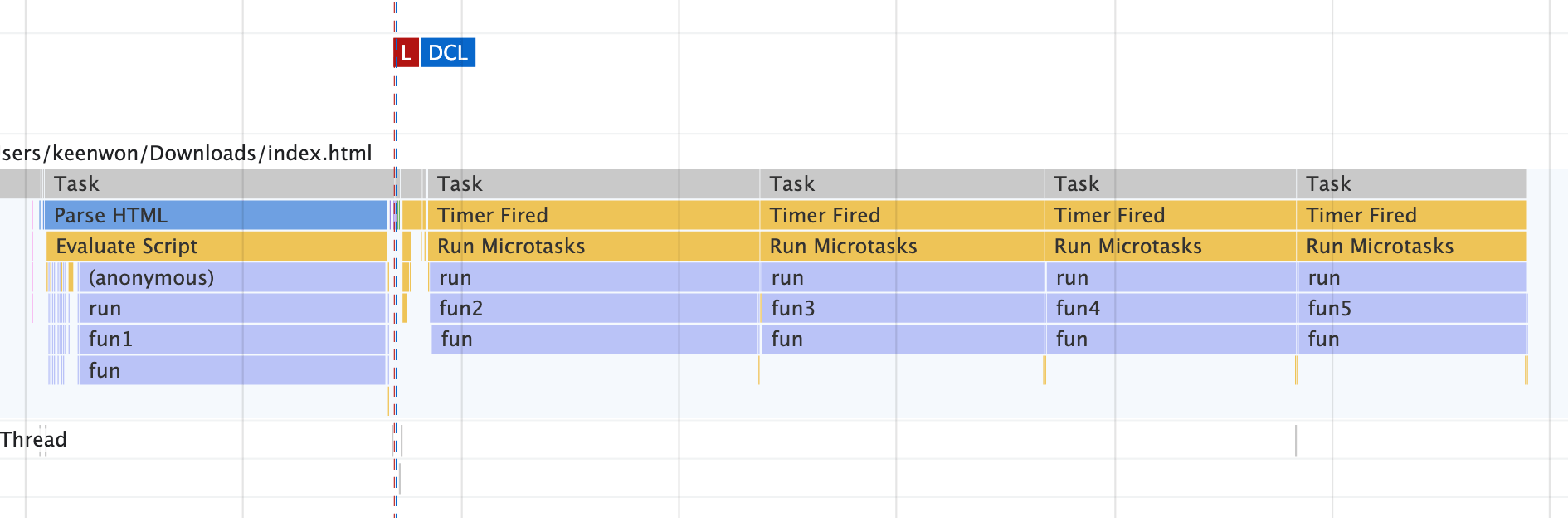
效果立竿见影!
不过,虽然要避免长任务,但也不是说把任务切的越碎越好。所以如果能按需执行 Yield Point 是最好的。有个新 API navigator.scheduling.isInputPending() 刚好可以实现此功能:
// 长任务是大于 50ms 的
let deadline = performance.now() + 50
while (tasks.length > 0) {
if (navigator.scheduling?.isInputPending() || performance.now() >= deadline) {
await yieldToMain()
// 延长 deadline
deadline += 50
continue
}
const task = tasks.shift()
task()
}
一些长耗时的复杂任务,如果不方便放在 web worker 里,可以试试 Yield Point。
4.6 CLS 的优化#
CLS 问题其实 99% 的情况下是可以完全解决的,只要注意,要明确「可替换元素」的尺寸或比例,保证页面骨架稳定。
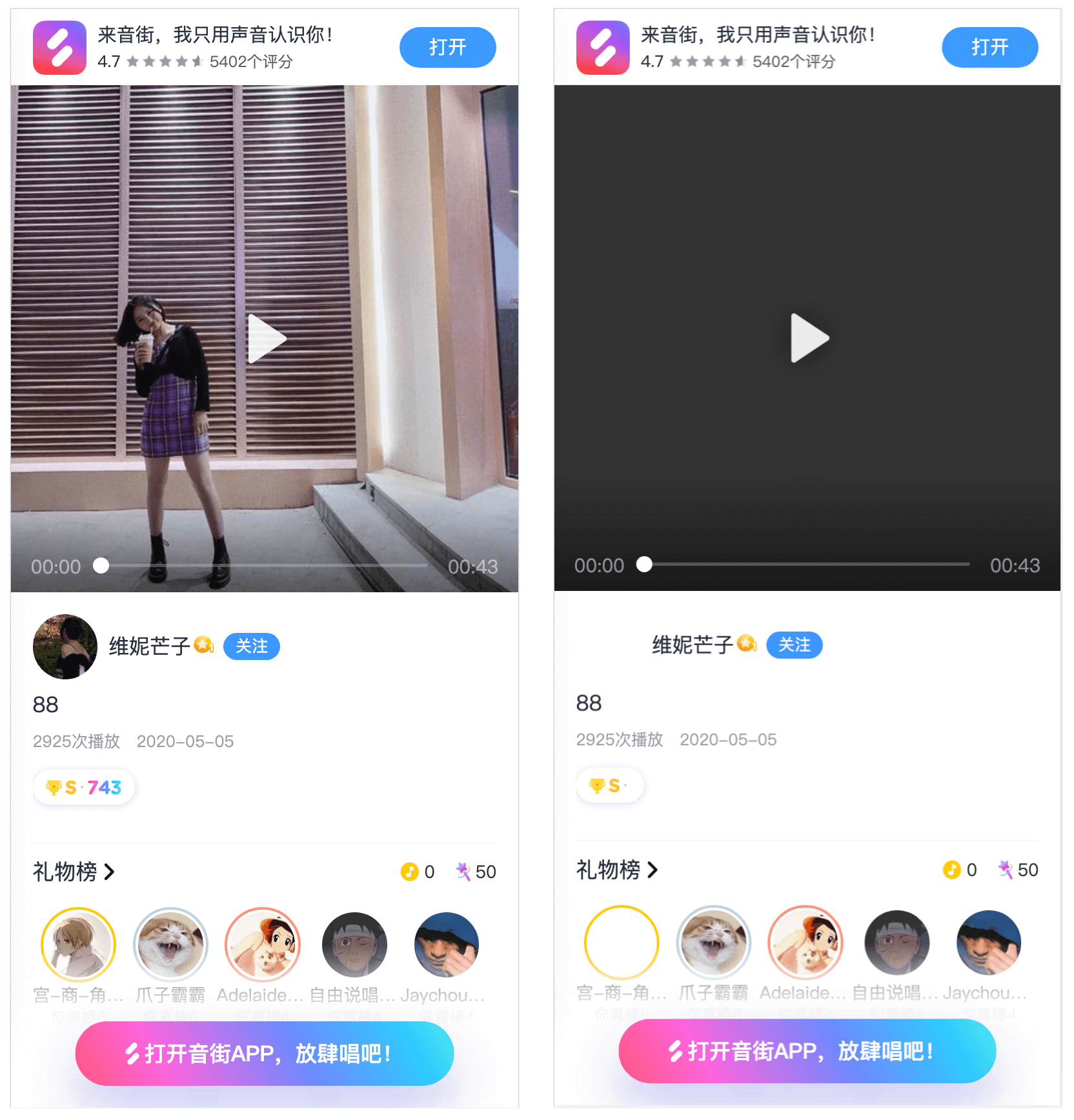
比如上面两个页面,当图片未加载时,页面整体的结构是稳定。
如果出现一些极端情况。比如页面中间部分的「推荐列表」,数据不可控,可能是 6 个,也可能是 8 个。这样我们没法明确高度,只能给个最小高度。那么此时,有两种选择:
- 加载到推荐列表后,通过 transform 等不引起 CLS 变化的方式,把「推荐列表」后的 DOM 向下移动
- 「推荐列表」和后面的内容先展示 loading 或者骨架,明确数据后再渲染出来
但最好还是不要设计这种交互,给用户的官感很差。
4.7 FID 的优化#
FID 相关的优化,除了刚才说的 Yield Point 之外,还有几种方法可以尝试
4.7.1 Web Worker#
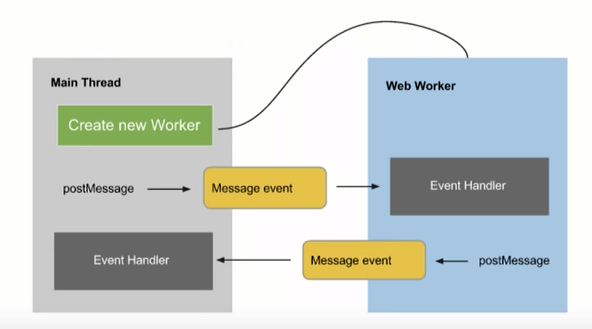
Web Worker 在日常开发中,使用场景比较有限,但是当遇到一些计算量大的操作时,可以考虑放入 Web Worker 执行,比如加解密操作(不过目前还是比较习惯直接通过 bridge 复用客户端的加解密能力)
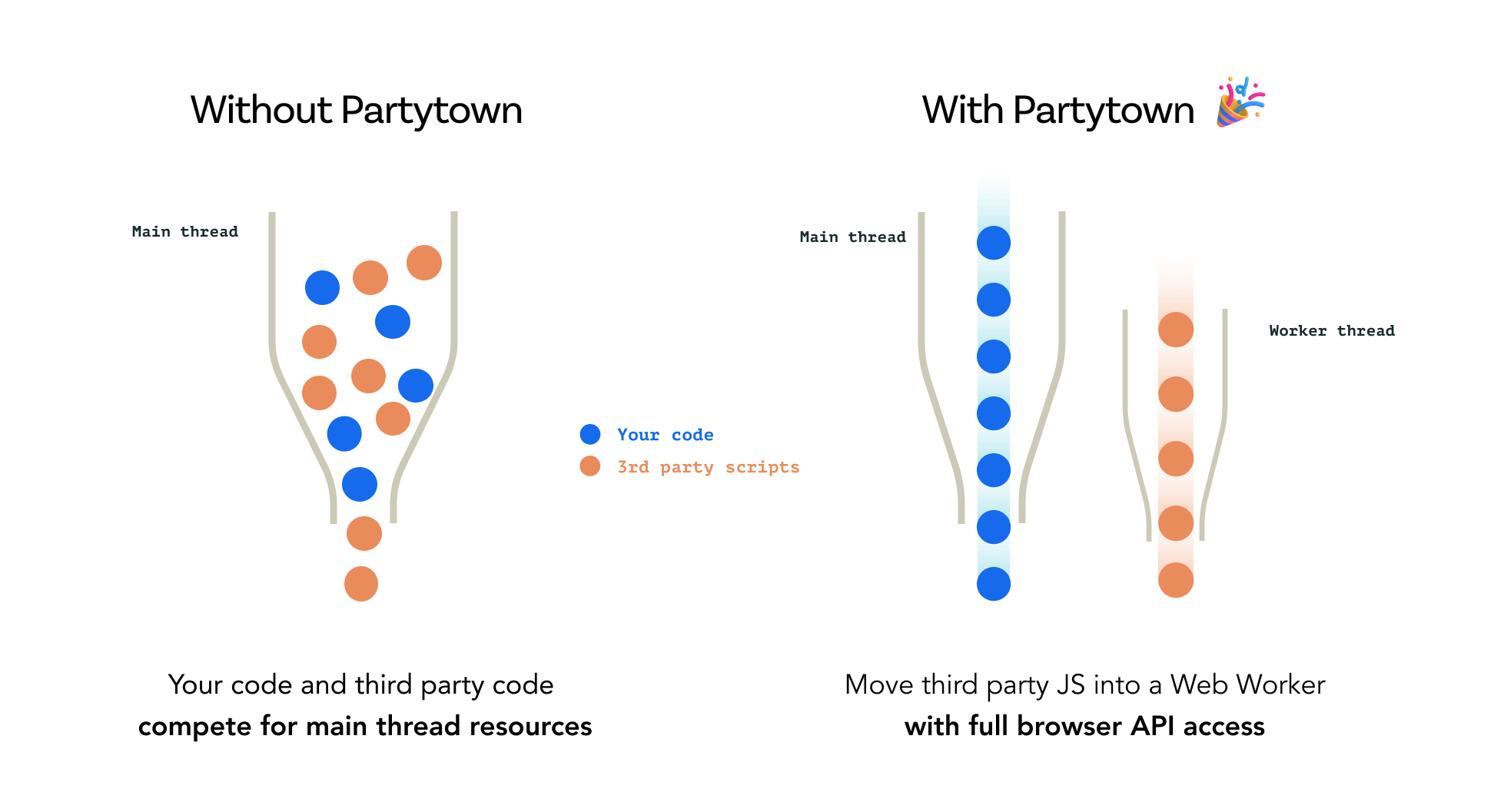
推荐一个很厉害的库,叫 BuilderIO/partytown,它可以把「资源密集型脚本」放到 Web Worker 里执行。
Web Worker 最大的限制是无法使用 DOM API。虽然可以在两个线程之间,创建消息系统来代理 DOM 操作,但 postMessage 用于 Web Worker 主线程通信的 API 是异步的,那么依赖于同步 DOM 操作的 JS 都会失败。
Partytown 的想法就很天才,它通过使用 JavaScript 代理、Service Worker 和同步的 XHR 请求,从 Web Worker 内部提供对 DOM API 的同步访问。
一些非常耗性能的库,比如用于反作弊、反垃圾,就可以尝试使用 Partytown。
4.7.2 避免不必要的前置运行逻辑#
为什么说要「避免不必要的前置运行逻辑」呢?因为,页面在加载的时候,通常有大量代码需要解析和执行,此��时过多的前置计算代码,会加重「加载时」的性能负担,影响 FID。
例如,用户在点击按钮时,不同端要做不同的跳转。端的判断完全可以在点击时处理,这个速度通常是很快的,不会 block 用户操作,没有必要页面一加载好,就预先判断。还有 url 上的参数获取,也是类似。
大家可以在开发模式下看一下 Performance 的火焰图,了解下每一步的执行情况。尽量把非必要的代码延后。
4.7.3 核心还是降低 JS 体积#
最后,优化 FID 的核心除了避免 Long Task,就是降低 JS 体积了,建议大家还是经常性的看看,代码中到底引入了哪些库:

比如说
- core-js 有没有配置对
- lodash 是不是全量引入了
- 有没有使用率很低的库,但却没有正确的异步加载
- 有没有一样功能的库引入了多了,比如
unfetch、axios、reqwest - 甚至是不同版本的同一个库,引入了多次
- ....
5. 国内与海外的异同#
接下来聊一下国内和海外的差异。虽然性能��优化的原理是相通的,但需要我们使用不同的手段来适应不同的环境。优化过程中,网络和设备的影响都比较大。先给大家分享一些数据。
5.1 网络环境#
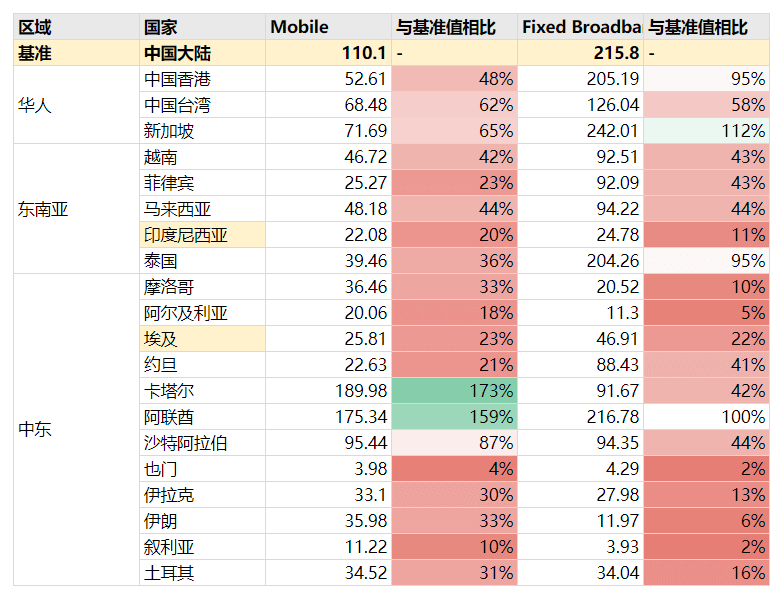
- 数据来源 https://www.speedtest.net/
- 时间是 2023-04
- 单位为 Mbps
可以看到,中国大陆的网络环境已经是极佳了。海外很难有这么好的网络。
5.2 设备情况#
5.2.1 iOS vs Android#
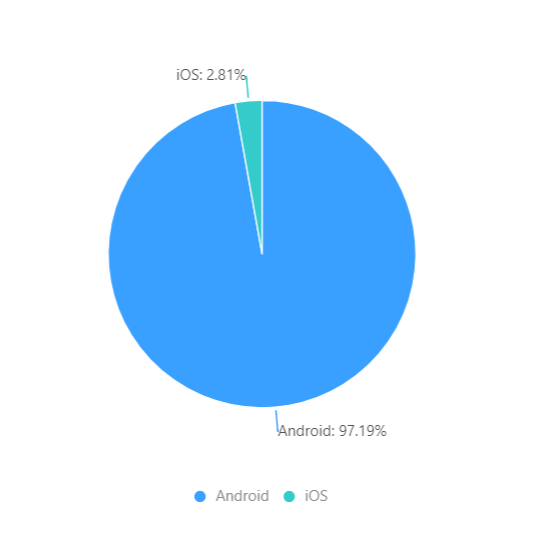
海外:
国内:
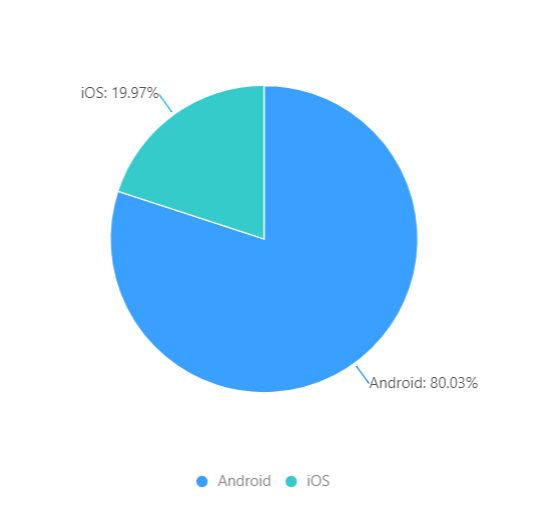
设备情况与当地的消费能力有关。比如 iPhone 占比,东南亚较低,而且 Android 普遍是中低端设备。
5.2.2 Webview 版本#
相较于 OS,对前端影响较大的其实是 Webview 版本
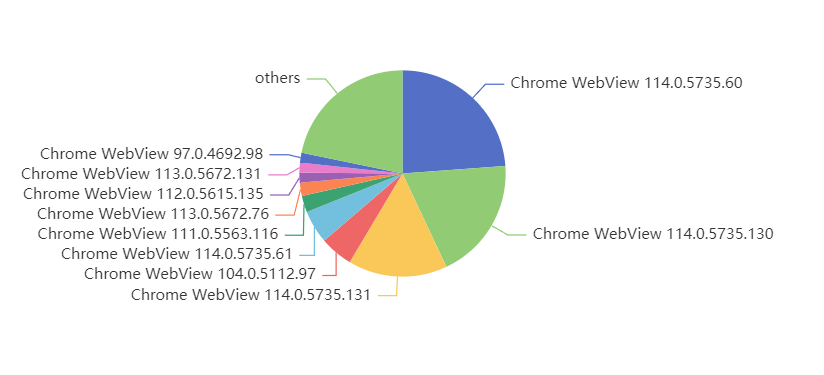
海外:
国内:
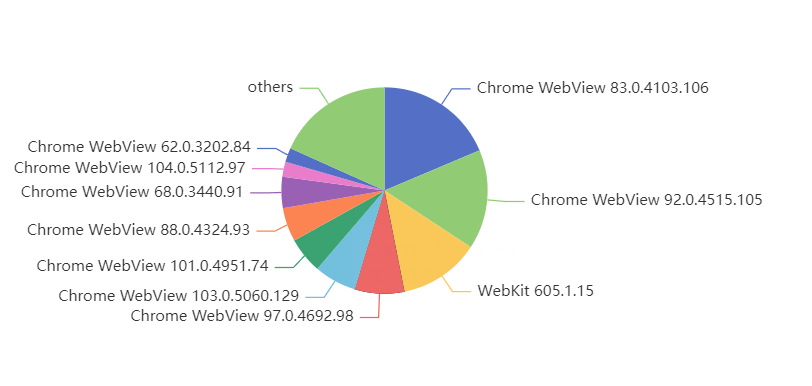
Webview 是可以在 Google Play 独立更新的,所以海外的版本通常比较新。国内都是跟随系统一起升级的。
5.3 性能现状#
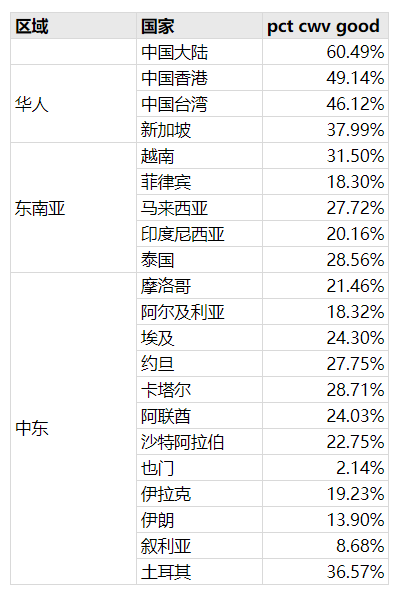
ahrefs.com 在 2022 年整理发布,数据来自 CrUX 的 500w+ 网站数据
通过 CrUX 的数据可以发现,国内的 cwv(core web vitals) 通过率还是比较高的。受限于环境,比如也门,同样的代码想达到国内的体验,几乎是不可能的。
5.4 优化思路#
结合海外的特点和我们的实践,海外项目应该考虑以下几点:
- 全站 CDN
- HttpDNS
- 离线包或者 Service Worker
- SSG 或者基于 edge runtime 的 SSR
- 现代 JavaScript + 适合的 browserslist (当然还有其他比较新的技术,比如 avif、webp,wasm)
建议使用全量离线包 + 轻�量化的前端框架(比如 preact)
6. 总结#
6.1 优化手段汇总#
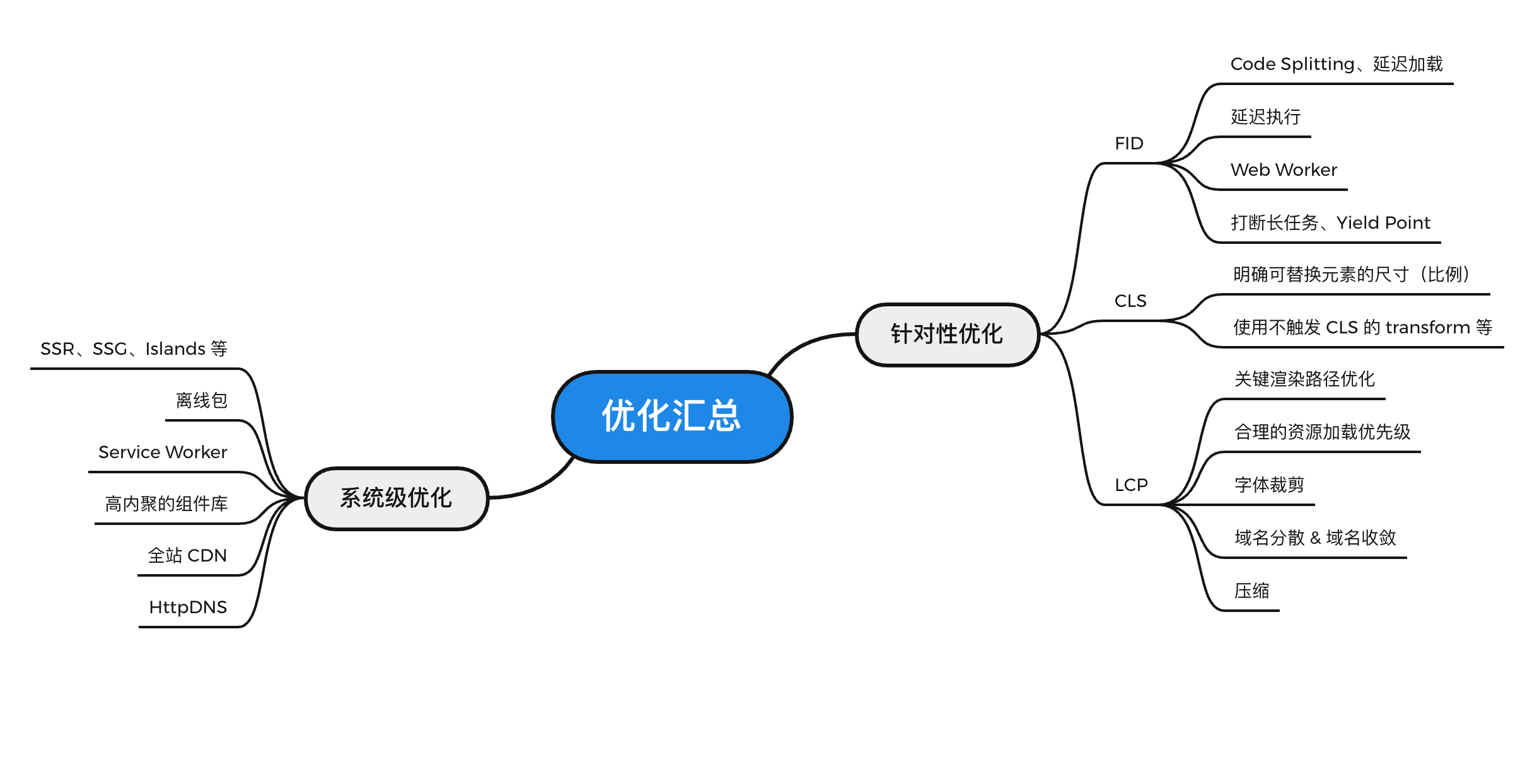
- 系统级优化
- SSR、SSG、Islands 等
- 离线包
- Service Worker
- 高内聚的组件库
- 全站 CDN
- HttpDNS
- 针对性优化
- FID
- Code Splitting、延迟加载
- 延迟执行
- Web Worker
- 打断长任务、Yield Point
- CLS
- 明确可替换元素的尺寸(比例)
- 使用不触发 CLS 的 transform 等
- LCP
- 关键渲染路径优化
- 合理的资源加载优先级
- 字体裁剪
- 域名分散 & 域名收敛
- 压缩
- FID
还有一些细节的点没写上去,但是不是说没有价值,比如:
- 使用 HTPP/2
- 开启 Gzip 或者更新的压缩算法
- 还有使用类似 rem 布局时,一些 JS 要前置,避免 relayout 带来的 CLS
- 还有全异步化化的 JS
<Script async />
这些应该都是一个合格项目的标配,上图列举的主要是额外的优化。
6.2 核心优化思路#
刚才讲了那么多优化方法,其实他们的「核心思路」都是一致的。
假设,在用户能看到页面,并且�与之交互之前,有这么几个步骤:
- step 1
- step 2
- step 3
- step 3.1
- step 3.2
- step 3.3
- step 4
那么优化的核心思路就是:
- 尽可能去掉一些关键步骤
- 尽可能提前一些重要步骤
- 尽可能优化某个具体步骤
第一点,尽可能去掉一些关键步骤。比如去掉 step2。SSR 相比于 CSR,用户能更快的看到页面,就是优化掉了「下载空白 HTML,下载并执行 CSS、JS,请求接口」这几步。
第二点,尽可能提前一些重要步骤。比如把 step 3.3 提到 step 3.1 之前。这个就是前面讲到的「优化资源加载优先级」。
第三点,尽可能优化某个具体步骤。比如 Yield Point,就是避免 JS 执行时产生 long task,优化 FID;再比如「图片压缩与格式的选择」,就是在尽可能的优化 LCP 元素的体积,提升加载速度。
通常来说,这三条思路的效果,是由高到低依次递减的。
本文是《网易 2023 专家坐堂》的约稿,总结了基于 Web Vitals 的前端性能优化经验,是近两年在公司多个国内外 APP 的开发过程中的经验。内容涵盖了之前发的几篇博客。

